פירסמתי ב-medium פוסט טכני על איך ליצור ספריה ב-Kotlin שניתן לפרסם גם כספרייה ב-NPM וגם כ-jar לשימוש ב-Java (באנגלית).
תהנו!

כרגע, אנחנו מנהלים את רוב התקשורת אצלנו בארגון בצורה של polling. לעיתים קרובות באים לשאול אותי למה אנחנו לא עוברים למודל תקשורת שהוא PubSub/Web Sockets/SSE וכד', ויש לא מעט מקרים שבהם פנימית צוותי הפיתוח משתמשים בטכניקות האלה פנימית בתוך המוצרים.
כדי לסייע להבין את השיקולים ולקבל החלטה מושכלת, הפוסט הזה ינסה לעשות קצת סדר בטכניקות השונות על יתרונותיהן והאתגרים שהן מציבות.
במהלך הפוסט נשתמש במושג "ספק" או "שרת" כדי לציין את המערכת שהיא בעלת המידע ויודעת שהוא התעדכן, ובמושגים "צרכן" או "לקוח" כדי לציין את המערכת המעוניינת במידע ומעוניינת לדעת שהוא התעדכן.
החלטה טכנולוגית תמיד צריכה להתקבל בהתאם לצורך. ה-Use Case שאנו עוסקים בו:
בפוסט אני לא מציין יתרונות ואתגרים המשותפים לכל השיטות. למשל, בכל השיטות להלן הלקוח יכול לחזור למצב מעודכן אחרי נתק ארוך גם בלי לטעון מחדש את כל המידע.
צריך להבדיל בין המבט הלוגי לבין המבט הפיסי באשר לשאלה הזאת.
ל-use case שהגדרנו אנחנו מחפשים רק שיטות שהן push לוגי, ולכן נדון רק בהן.
נעשה מעבר קצר על רוב השיטות הקיימות להעברת עדכונים ונראה מה מאפיין אותן. נתעסק בעיקר בנושא של איך צרכן מקבל עדכוני מידע ופחות באיך הוא עושה טעינה ראשונית שלו.
השיטה הפשוטה ביותר. הרעיון הוא שבאופן מחזורי, מדי כמה זמן (קבוע או לא) הצרכן פונה לספק כדי לקבל תמונת מצב עדכנית (השם "poll" בא מהמילה "סקר", כלומר דגימה).
בגרסה הפשוטה ביותר של polling הצרכן מושך את המידע במלואו, בגרסה הבינונית רק רשומות שהתעדכנו ובגרסה המורכבת ביותר הוא מקבל גם מה התעדכן (ברמת עמודות), כאשר הגרסה האחרונה מורכבת משמעותית מהשתיים הראשונות ולכן חלק מהיתרונות של polling לא חלים עליה. הניתוח כאן מתייחס בעיקר לגרסה הבינונית.
יתרונות:
אתגרים:
לשיטה הזאת יש כמה וריאציות. הבסיסית והנפוצה ביותר היא שהלקוח פונה לשרת עם שאילתה, אבל כל עוד אין עדכון השרת לא עונה וה-connection נשאר פתוח במצב ממתין. במקרה שמגיע עדכון, השרת עונה ללקוח ואז הלקוח פונה שוב. אם הרבה זמן אי עדכון, הלקוח יקבל timeout ויפנה שוב.
יתרונות:
אתגרים:
השיטה הזאת פועל בשיטה של הימנות - הצרכן פונה לספק ומספר לו לאיזו שאילתה הוא מעוניין להימנות. הספק מחזיר לו state נוכחי, ושומר לכל צרכן inbox עם הודעות רלוונטיות. בכל עדכון הספק מחַשב עבור אילו צרכנים העדכון רלוונטי ושומר הודעה על עדכון ב-inbox שלהם. הלקוח עושה polling מול הספק כדי לבדוק אם יש לו הודעות חדשות.
יתרונות:
אתגרים:
בשיטה הזאת פותחים ערוץ פתוח בין הספק לצרכן, שבו השרת יכול לדחוף מידע אל הלקוח (SSE מבוסס HTTP בעוד ש-Web Sockets מבוסס TCP). מדובר בטכנולוגיות סטנדרטיות שנתמכות על ידי דפדפנים מודרניים (אבל לא על ידי הישנים). WS היא במידה רבה השיטה "המגניבה והחדשנית" היום - צריך לזכור רק שהיא באה לתת מענה למקומות שפעם היו משתמשים ב-socket פתוח.
Subscription של GraphQL, למשל, מממשים לרוב באמצעות Web Sockets.
יש עוד וריאציות שמבוססות על socket פתוח (כמו יכולות ב-HTTP2, או פתיחת בקשת HTTP והשארתה בחיים על ידי הספק ע"י הזרמה פריודית של נתונים רק כדי למנוע timeout, משהו שנשמע כמו long polling אבל בלי פתיחה מחדש). הוואריאציות מתאפיינות ביתרונות ואתגרים דומים.
יתרונות:
אתגרים:
השיטה הזאת דורשת bus ארגוני (=message broker) שעליו יופצו כלל העדכונים (אם אתם חושבים: "אבל לא חייבים להעביר את התוכן של העדכון!", זאת תהיה השיטה הבאה). יהיו אוסף של topic-ים שיסוכמו בין ספקים לצרכנים, והספקים יעבירו עליהם את כל העדכונים שנוצרו. הצרכנים ירַשמו לעדכונים מול ה-bus.
יתרונות:
אתגרים:
השיטה הזאת עושה push על עדכונים (באמצעות Long Polling, Web Socket או PubSub - נכנה אותם "PLW" לצורך סעיף זה בלבד), אך נשלחת רק הודעה על עצם קיום עדכון בלי תוכנו - יופצו עדכונים בצורה "נוצרה הזמנה חדשה", "מטוס 16548 עודכן", "כלב 314 נמחק" וכד'. הספק מעביר לצרכנים את כל ההודעות (או בפילטור בסיסי קבוע - כמו topic) והצרכן מחליט מה מתוך כל הדברים האלה מעניין אותו, ואז מבצע שאילתה מול הספק כדי לקבל את הנתונים.
באופן כללי, השיטה הזאת היא שילוב של polling עם אחת משיטות PLW, ובהתאם מתאפיינות בשילוב של יתרונותיהן וחסרונותיהן.
יתרונות:
אתגרים:
המסקנה המרכזית מכל הנושאים האלה - לכל שיטה יש יתרונות אך היא גם מציבה לא מעט אתגרים. ישנן כמובן גם שיטות נוספות בעולם, אך רובם דומות לאלה המפורטות כאן.
מגוון השיקולים הרחב לא מאפשר לתת כללי אצבע ברורים ומאד תלוי ב-use case ובצוות המממש. ניסיתי לרכז כאן דוגמאות למקרים בהם כדאי להשתמש בשיטות שונות. תוכלו לשים לב שהדוגמאות לא זרות - צריך להיכנס לעומקם של היתרונות והאתגרים כדי לבחור. יש לשים לב - אלה השיקולים עבור ה-use case שהוצג בהתחלה, ל-use case-ים אחרים לחלוטין יש יתרונות ואתגרים נוספים (לדוגמא - WS השיטה היחידה שמאפשרת תקשורת דו כיוונית בזמן אמת בין הצרכן לספק. רק חלק מהשיטות מאפשרות streaming של מידע או העברה יעילה של מדיה) - התעלמנו במכוון ממכלול השיקולים האינסופי כדי להתכנס למשהו מובן.
| שיטה | תנאים בהם השיטה מצטיינת |
|---|---|
| Polling |
|
| Long Polling |
|
| Inbox Polling |
|
| Web Socket / SSE |
|
| PubSub |
|
| הפצת מידע אודות עדכון |
|
כאמור, הפוסט הזה תפקידו רק לציין את השיקולים השונים שיכולים להשפיע על הבחירה. לעיתים אנשים שונים תופסים אופציה אחת כ-"הכי טובה", "הכי מודרנית" או "הפתרון הנכון" - אבל האמת תמיד מורכבת יותר מאמירות כאלה.
למי שמעוניין להעמיק יותר, אני רוצה להמליץ על הספר הנהדר High Performance Browser Networking מאת Ilya Grigorik, בהקשרנו הפרק Browser APIs and Protocols שמסביר חלק מהטכולוגיות שנזכרו פה לעומק. הוא מציג הסברים משלו לשיקולים לבחור בטכנולוגיה כזאת שלא תמיד זהים לשלי, חלקית בגלל דעה וחלקית בגלל use case שונה.
חושבים ששכחתי משהו? רוצים להעלות עוד שיקולים רלוונטיים? מזמנים לרשום בתגובות!
“Negative results are just what I want. They’re just as valuable to me as positive results. I can never find the thing that does the job best until I find the ones that don’t.” - Thomas A. Edison
כשאנחנו מחליטים לפתח משהו, יש לנו השערה
(או בשמה המדעי - 'היפותיזה'). יכול להיות שאני סטרטאפיסט שחושב שהעולם רוצה
אפליקציה להתאמת בגדים לחתולים, יכול להיות שאני איש UX שחושב שאם כפתור יגדל
ב-5px ויהיה בצבע כתום, אז יותר אנשים ילחצו עליו ויקנו מוצרים, ויכול להיות
שאני מְפַתֵּח שחושב שאם אשנה את הקונפיגורציה של mongoDB להיות
replication.secondaryIndexPrefech: _id_only אז זה יפתור את
בעיית הביצועים שיש לי ולא יפריע למשתמשים או שאני חושב שהקוד שלי עובד טוב
ועמיד בתקלות רשת.
בכל המקרים האלה, הצגנו היפותיזה ואנחנו מתחילים לפתח בכיוון.
אבל איך נדע אם מה שחשבנו זה אכן נכון? ואיך נדע אם מה שפיתחנו זה טוב? אולי העולם לא רוצה אפליקציה כזו, אולי הכפתור הכתום ירתיע משתמשים או יבלבל עיוורי צבעים, אולי הקונפיגורציה החדשה תיצור נזק ואולי בגרסה החדשה של התוכנה נוסף באג שקורה רק ב-production או רק בשילוב עם מערכת אחרת והוא יגרום לה להתרסק.
יש לנו חוסר ודאות בקבלת ההחלטות שלנו. כדי להתמודד עם זה, יש לנו 2 אפשרויות:
אפשרות 1 דורשת להעסיק הרבה אנשים חכמים בלדבר על אפשרויות, זמן שבו הם לא מייצרים תוצרים בעצמם, לא תורמים מחוכמתם לאנשים אחרים בארגון ודורש גופי הנהלה שיבחרו מי מכל האנשים (המומחים יותר מהם) צודק. התוצאה של זה היא שאנחנו רק מעלים את ההסתברות שההיפותיזה נכונה, אבל כולנו נרגיש טוב כי "התקבלה החלטה אחרי המון עבודה ומחשבה". נשקיע הרבה משאבים בלפתח לפי ההחלטה, נבטיח ללקוחות שלנו כל מיני זמנים, ובסוף נגיע ל-production ו(אולי)נגלה שההשערה שלנו הייתה מוטעית. וגם לא יהיה לנו הרבה מה ללמוד במקרה שזה לא הצליח.
כמובן שהחיסרון של אפשרות 2 הוא הסיכון הגבוה שהיא מציגה.
בניהול סיכונים לומדים ש:
עוצמת הסיכון היא: סיכוי x נזק
כלומר יש שתי אפשרויות להקטין סיכון: הורדת הסיכוי למימוש הסיכון (זה מה שאפשרות 1 מנסה להשיג) או להוריד את הנזק שיגרום מימוש הסיכון - זה מה שאנחנו נתמקד בו באפשרות 2.
“One of the reasons people stop learning is that they become less and less willing to risk failure” - John W. Gardner
כדי להפחית נזק באופן מועיל, עלינו תחילה להעריך מה כמות הנזק שעשויה להיגרם. את הנזק נעריך ביחידות המידה הרלוונטיות (למשל כסף, אמון, יכולת או שילוב שלהם. נכנה את יחידות המידה כאן DU). כשאנחנו מנסים להעריך כמה נזק יגרם, יש כמה היבטים שלינו לחשוב עליהם:
כל אחת מהתשובות האלה משפיעות על כמות הנזק (באופן גס סך הנזק הוא מכפלה שלהם), ולכן אנחנו נוכל לתקוף כל אחד מההיבטים האלה בנפרד כדי להקטין את הכמות הנזק. במקרים רבים אנחנו נקטין את פוטנציאל הנזק עד שהסיכוי להתממשות הסיכון תרד מספיק שנוכל להעלות את הפוטנציאל בחזרה.
נעבור על כל אחד מההיבטים האלה ונראה מהם הדרכים שעולם התוכנה מציע לנו כדי להתמודד איתם. כמו תמיד, מדובר כאן באוסף של כלים שזמין לנו ועלינו לבחור באילו מתוכם נרצה להשתמש. סביר מאד להניח שאם ננסה להשתמש בכולם ביחד יווצר יותר נזק מתועלת...
אחד הדברים המרכזיים שנרצה לעשות הם להקטין את כמות האנשים שנחשפים לבעיה. זה גם מקטין מאד את הנזק העקיף שיכול להיגרם למערכת (כמו חוסר אמון מצטבר במערכת. במקרה של פיתוח פנימי ב-enterprise, למשל, לעיתים קרובות המשתמשים מחליפים חוויות ובעיות משותפות מעצימות את חוסר האמון).
אחת הדרכים לעשות את זה היא Canary Testing. בקצרה, בשיטה הזו אני מתקין גרסה חדשה לצד הגרסה הקודמת ומפנה אליה משתמשים באופן הדרגתי. למשל, הפנייה של 1% מהמשתמשים ואז השוואת המדדים לגרסה הראשית (אחוז conversion, מדדי ביצועים וכו'). אם המדדים עונים על המצופה, מגדילים את אחוז האנשים בהדרגה עד שמגיעים ל-100%, ואז אפשר להוריד את הגרסה הישנה. האנשים יכולים להיבחר אקראית או לפי מאפיין מסויים (מיקום גיאוגרפי, נרשמים לתוכנית beta וכו'). מדובר בשיטה נפוצה מאד.
העבודה בשיטה כזו מאפשרת לנו להגביל מאד את כמות הנזק בסיכון בזמן שאנחנו מקטינים בהדרגה את הסיכוי להתמשות הסיכון.
שיטה מתקדמת יותר לביצוע התהליך הזו היא Feature Toggle, שמאפשר לנו לשלוט ברזולוציה מאד גבוהה בחשיפה של תכולות חדשות. יש מאמר מפורט שמסביר איך עושים את זה.
כמובן גם A/B Testing יכול לשמש במקרה הזה, אם כי לעיתים קרובות הוא מערב כמויות גדולות של משתמשים ומשמש להגבלת משך זמן הנזק.
לפעמים הנזק שיווצר למספר קטן של אנשים הוא גדול מדי, או שלא ניתן להגביל את השינוי למספר קטן של אנשים. במקרה כזה אפשר להקטין את הנזק לנפגעים.
שיטה אחת שבה נוקטים כדי להקטין את הנזק מכוּנה "mirroring", "shadowing" או "dark launch" (המושג האחרון משמש לפעמים גם ל-feature toggle). השיטה הזאת אומרת שמתקינים את הגרסה החדשה לצד הקודמת, ושֹם proxy בין בלקוחות לבין המערכת שמשכפל את כל התנועה הנכנסת לשתי הגרסאות. את התשובה מהגרסה הקודמת הוא מחזיר ללקוח, והתשובות משתי הגרסאות נשמרות לטובת השוואה שמוודאת שאין שינויים לא צפויים בין הגרסאות. בנוסף משווים בין מדדי ביצועים שונים בין הגרסאות. לאחר זמן מה במצב כזה, הסיכוי להתממשות הסיכון ירד מספיק שאפשר להעביר את הגרסה לשימוש של משתמשים.
שיטה אחרת לטפל במקרים מסויימים היא automatic degrade - במקרה שיכולת מסויימת מפסיקה לתפקד כצפוי, יש כניסה של היכולת ל-"מצב בטוח". זה יכול לקרות על ידי החזרת התעבורה לגרסה הקודמת או ע"י התנהגות ברירת מחדל כלשהי שנכנסת לפעולה (הדוגמה הקלאסית היא מודול המלצות על מוצרים. במקרה שהמודול הזה עובד בצורה לא תקינה, המערכת מכבה אותו וממליצה לכל המשתמשים על מספר מוצרים קבועים מראש)
לפעמים יש נזק חמור שעשוי להיגרם למשתמשים או לארגון אבל אם הוא נמשך זמן קצר יחסית זה לא נורא. במקרה הזה שיטה שמאפשרת לנו להגביל את משך זמן הנזק תהיה מאד יעילה.
הדוגמה הקלאסית לזה היא A/B Testing. בטכניקה הזו אנחנו מחלקים את המשתמשים לקבוצת ניסוי וקבוצת בקרה, כאשר רק קבוצת הניסוי חווה את השינוי. במקרה שהמדדים של קבוצת הניסוי טובים פחות משל קבוצת הבקרה, מחזירים את כל התעבורה לגרסה הקודמת. ההנחה כאן היא שהנזק שנגרם בזמן הניסוי (למשל ירידה בהכנסות) הוא נסבל לזמן קצר.
שיטה אחרת שעוסקת בצד ההיפותזות הטכניות היא Green/Blue Deployment. הרעיון הוא שמתקינים את הגרסה החדשה ("ירוקה") של המערכת במקביל לגרסה הקיימת ("כחולה") ומעבירים אליה את המשתמשים (זאת סביבה שלמה ולא רכיב, ולרוב גם לא מדורג - בניגוד ל-canary testing). במקרה שמשהו לא עובד טוב, בלחיצת כפתור מחזירים את המשתמשים לעבוד על הסביבה הכחולה. זה מאפשר לנו להגביל את הנזק לזמן שלוקח לנו להבין שהוא קורה.
גם שילוב של circute-breaker עם automatic degrade (הנ"ל) , כלומר כשה-circute פתוח מפנים להתנהגות ברירת מחדל. זה מאפשר לזהות את הנזק תוך מספר מועט של פניות ולא לחשוף אותו למשתמשים.
בארגון מודרני הבאת יכולת מהר ל-production היא הכרחית. ולכן חברות רבות אימצו תפיסות של "embrace the change" או אפילו "fail fast + embrace failure" - הן בחרו להתמקד פחות בהורדת הסיכוי להתממשות הסיכון מראש (תהליך שמעכב הגעה ל-production) ולאמץ גישה שמקטינה את הנזק שמימוש הסיכון עשוי ליצור.
עם זאת, צורת העבודה האג'ילית כן מעודדת עבודה שמקטינה את את הסיכוי להתממשות הסיכון - התקנות תכופות ומפגש מוקדם עם משתמשים. ככל שמתקינים לאחר זמן פיתוח קצר יותר נעשו פחות שינויים בתוכנה ולכן הסיכון שמביאה גרסה חדשה הוא נמוך יותר. לכן שילוב של עבודה אג'ילית עם הטכניקות שהזכרנו להקטנת מחיר הטעות מביאות לסיכון נמוך במיוחד בהבאת גרסא חדשה ל-production. אחד המאמרים הכי טובים שיצאו על הנושא הזה ואיך אפשר ליישם עלייה ל-production שבאמת עוזרת לנו לאמת היפותזות הוא Making sense of MVP של Henrik Kniberg.
ארכיטקטורת Microservices צוברת תאוצה, ועם עליית הפופולריות תמיד גם מגיע השלב שבו הרבה אנשים מתחילים להאמין שארכיטקטורה זו היא היא המפתח לפתרון כל צרות העולם, בלי להבין את המורכבות שמגיעה עם הארכיטקטורה הזו.
בהרצאה קצרה זו Satyajit Ranjeev מציג מהניסיון שלו חלק מהמורכבויות שמגיעות עם ארכיטקטורה זו. ההרצאה המלאה.
התשובה הנכונה: ע"פ Bounded Context. התשובה הלא נכונה (שהם ניסו): על פי ישויות. חלוקה כזו מובילה למשל למערכת בלוגים שבה יש שירות של פוסטים, שירות הודעות, שירות תגובות וכו', כאשר לאו דווקא החלוקה הזו היא חלוקה שמונעת תלויות.
הדבר השני שהם לא הבינו בהתחלה היה "מה זה מיקרו". הם הגיעו די מהר ל-73 שירותים לצוות של 5 אנשים, וזה יצר תלויות, מורכבויות וצורך לשינויים רבים. למצוא את הגבולות הטבעיים של ה-context זה לא קל.
החברה שהמרצה עובד בה עוסקת בהעברת כספים. הם בחרו להשתמש ב-Kafaka כי הוא מבטיח שכל שדר מגיע לפחות פעם אחת. עדיין בערך 1% מהשדרים מגיע פעמיים, וכדי להבטיח Idempotency צריך לשמור את השדרים. הם בחרו בשביל זה להשתמש ב-event sourcing, וזה היה להם מאד נחמד כי אפשר לראות בדיוק מה קרה וגם לשחזר מידע במקרה של בעייה. איפה שומרים את כל ה-event-ים? הם בחרו להשתמש ב-Kafka עצמו כי הוא מבטיח סדר (per partition - זה הכריח אותם לעבוד רק עם partition אחד), וכל פעם ששירות עולה הוא בונה מחדש את המצב. באופן צפוי, היה topic אחד שהגיע ל-9 מליון הודעות ולקח לשירות המון זמן לעלות. חשוב גם לזכור שב-Kafka אי אפשר למחוק מידע מ-topic (רק מההתחלה אבל לא מהאמצע), ולא בטוח שהוא המוצר הכי מתאים ל-Event Sourcing.
כדי להתמודד עם עלייה ארוכה במקרה של topic-ים מאד גדולים, הם החליטו ליצור snapshots. הם שקלו שיטות שונות והחליטו ללכת על DB לכל שירות, וזה אכן פתר את בעיית האיטיות בעלייה. הם שמרו ב-PostgreS את ה-snapshots שרלוונטיים לשירות, ומה הנקודה האחרונה שנצפתה ב-Kafka.
הם עבדו עם docker ו-Fleet.
אחד הדברים החשובים להבין כשנכנסים ל-Microservices זה שיש לזה עלות גבוהה ב-operations. נדרש להשקיע הרבה מאמץ רק כדי להשאיר את המערכת רצה. הם ידעו את זה מראש, אבל לצוות קטן זו עלות מאוד גבוהה - לטפל בסביבה, לטפל בניטור...
יש מאמר של Martin Fowler שאומר You must be this tall to use microservices. מומלץ לקרוא לפני שמתחילים.
עוד משהו מעניין שהם עשו זה להוציא מה-JIRA ספירה של Task-ים שעוסקים
בתשתיות הריצה. זה נראה ככה:

ביום שלפני תחילת הכנס עצמו היה יום סדנאות. אני הצטרפתי לסדנא בהדרכת Uwe Friedrichsen שעסקה בנושא Resilient software design in theory & practice. סדנא מאד מעניינת. אני מביא פה כמובן רק תקציר של הנקודות החשובות, אפשר לשמוע תקציר של הסדנא ע"י Uwe עצמו בהרצאה שהוא נתן למחרת בכנס (שקפים), ומי שיצליח להשתלב בסדנא שלו בהמשך - מומלץ!
 |
| אנחנו במהלך הסדנא |
אנחנו כותבים תוכנה כדי להביא ערך עסקי. אבל היא מביאה ערך אמיתי רק עם התוכנה רצה ב-production ועובדת. לכן לעובדה שתוכנה רצה ועובדת ב-production יש ערך עסקי אמיתי, שהוא לא תמיד גדול יותר או קטן יותר מדברים אחרים, ובאחריות ה-product owner להעריך אותו ולשלב משימות resilience ב-backlog שלו.
מכיוון שבלי שתוכנה רצה ועובדת היא לא מביאה ערך עסקי, הנושא של זמינות (Availablilty) הוא נושא חשוב מאד בתוכנה. אבל מהי בכלל זמינות? איך מודדים אותה?
יש נוסחא פשוטה:
| Availibilty= | MTTF |
| MTTF+MTTR |
(MTTF=Mean Time To Failure, MTTR=Mean Time To Recovery)
כלומר הזמן שהמערכת רצה בצורה תקינה חלקי כמות הזמן הכוללת.
כדי להגדיל את הזמינות (לגרום לנוסחא לשאוף ל-1) יש לנו שתי אפשרויות: להגדיל את ה-MTTF (למנוע כשלים) או להקטין את ה-MTTR (לשפר את היכולת שלנו להתמודד עם כשלים). קלאסית, תמיד עסקנו בהגדלת ה-MTTF ע"י שיפורי תהליכים והשקעה בתשתיות. אבל העולם מתקדם למערכות מבוזרות ולמערכות התלויות במידע מבחוץ:
A distributed system is on in which a failure of a computer you didn't even know existed can render your own computer unusable. - Leslie Lamport
במערכות כאלה מניעת כשלים היא הרבה יותר קשה, כיוון שכשלים ברמת התשתית תמיד קורים. מחקר של מייקרוסופט שבדק את כשלי החומרה ב-Data Center שלהם מדבר על חציון של 40.8 כשלי network link ליום, כאשר חציון הזמן לתיקון הכשל עומד על 5 דקות. החציון המוערך של כמות הפקטות שעובדות בכל כשל כזה הוא כ-59,000. מחקר אחר מראה שגם בין אתרים של אמזון (שמצטיינים ב-latency נמוך) יש לפעמים latency חציוני של למעלה מ-350 מילישניות.
לכן האופציה השנייה, שבה אנחנו מתמקדים במערכות מבוזרות, היא הקטנת ה-MTTR, כלומר ליצור מערכת עמידה [עמידות = היכולת של מערכת להתמודד עם מצבים לא צפויים בלי שהמשתמש מרגיש (במקרה הטוב) או תוך רידוד יכולות מבוקר (graceful, במקרה הרע)]. או בניסוח של משפט המפתח בהרצאה:
Do not try to avoid failures. Embrace them.
כשאנחנו מדברים על מצבים בלתי צפויים בתוכנה, אנחנו מדברים על 3 סוגים (או 3 שלבים) של בעיות:
כלומר, מה שאנחנו מנסים לעשות הוא למנוע מ-Fault להפוך ל-Error ובעיקר למנוע מ-Error להפוך ל-Failure.
עוד אזהרה אחת שחשוב להגיד: צריך להימנע מ-"מלכודת ה-100% זמינות". זה מאד קל ל-product owner להגיד: "זמינות זה עניין טכני באחריות המפתחים. אתם צריכים לעשות מה שצריך כדי שהמערכת תהיה תמיד זמינה". אבל זו גישה לא נכונה - האם עכשיו עדיף שלא נפתח שום יכולת במערכת כי נשקיע רק בזמינות? או לחילופין, שניתן מערכת עם המון יכולות אבל שלא עובדת חצי מהזמן?
לזמינות של המערכת יש ערך עסקי. התגובה של המערכת לכשלים היא החלטה עסקית. וצריך לתעדף את התגובות האלה ביחס ליכולות אחרות של המערכת. צריך להכניס למערכת מדידה של אובדן הכנסות (או משאב אחר) עקב כשלים במערכת או איטיות במערכת.
כאמור, במערכת מבוזרת אנחנו נמצאים בסביבה מבוזרת, ולכן לא ניתן למנוע בעיות לחלוטין. אנחנו יכולים רק להוריד את ההסתברות שלהן וההשפעה שלהן. לכן נראה עכשיו כלים כדי לתכנן מערכת עמידה.
הערה כללית לסדנא: כל הדברים האלה הם לא חוקים, אלא נקודות שצריכות להיות במחשבות שלנו. צריך להתאים את הפתרונות לעולם התוכן שלנו, לנסות, למדוד, ליצור feedback loop שיאפשר לנו להבין מה עובד ומה רלוונטי, ולהבין מה מתאים לנו ולמה.
כשאנחנו ניגשים לתכנן מערכת עמידה, יש כמה שלבים שאנחנו רוצים לעבור:
ישנן שתי החלטות ליבה שעלינו לקבל כאשר אנחנו מתכננים מערכת: בידוד רכיבים (isolation) ובחירת שיטת תקשורת.
בהקשרי עמידות המערכת אסור שהמערכת תטופל כיחידה אחת - צריך לחלק את המערכת לאזורים מבודדים שבמקרה של כישלון כל אחד מהם כושל בנפרד. חלוקה ל-Microservices לא מספיקה אם השירותים השונים תלויים אחד בשני ויגרמו לכשל אחד של השני.
כאשר מתכננים את החלוקה לרכיבים של מערכת יוצרים משהו שנקרא bulkheads: בחירה של המחיצות ואופן החלוקה של המערכת. אפשר לעשות זאת ע"י חלוקה ל-Microservices, או על ידי חלוקה ל-Actors למשל.
אבל לעשות חלוקה שכזאת זה קשה! למה? כי אם שירות A תלוי בשירות B, שירות B עדיין יכול למנוע משירות A לעבוד (כן, אפילו אם שירות A משתמש ב-circute breaker). ואם גם שירות B תלוי בשירותים אחרים, והם תלויים בשירותים נוספים, אז גם אם כל אחד זמין ב-99.99999% מהזמן הזמינות של A יכולה לרדת משמעותית, אפילו ל-75%. להכניס את כל השירותים לאותו bulkhead רק יחזיר אותנו לבעיות המונוליט. גם שימוש בכלים אחרים שאנחנו מכירים מהנדסת קוד, כגון DRY, פירוק לפונקציונאליות, שכבות וכד' לא יעזרו לנו.
מה כן יעזרו לנו? העקרונות הבסיסיים של חלוקה לרכיבים: High Cohesion, Low Coupling יחד עם speration of concerns הם קריטיים כשחוצים את גבולות ה-process. זהו נושא שאנחנו עדיין לומדים אותו בתעשייה ולא התקדמנו הרבה מאד בתחום (למשל מאז המאמר הזה מ-1972).
איך מתחילים לעשות חלוקה שכזאת?
אחרי זה צריך למצוא את הדרך הקצרה ביותר לענות לבקשות - יותר מדי hops בדרך מקטינים את הזמינות ומגדילים את ה-delay, ולכן אנחנו נחפש תמיד את הדרך הקצרה ביותר להחזיר את התשובה ונשאף להקטין את כמות הקריאות (RMI) שאנחנו עושים בתהליך. את העיקרון הזה חשוב לאזן מול המשיכה לשבור את ה-seperation of concerns ולחזור למונוליט כדי להקטין את כמות הקריאות - צריך לאזן בין שני הדברים האלה. Cache-ים יכולים לעזור לנו לפתור חלק מהבעיות האלה, אבל חשוב לזכור ש-cache לא יתקן עיצוב לא טוב והוא מביא איתו מורכבויות משלו.
עוד משהו שחשוב בשביל לעשות isolation טוב: לוותר על Reusability מחוץ לגבולות ה-process. גם אם אפשר להשתמש בשירות מסויים בכל מיני מקומות, זה לא אומר שכדאי לעשות את זה. השימוש החוזר בשירות (לעומת האלטרנטיבה של, לדוגמא, לשתף jar) גורם לעוד hop בתהליך ולכן פוגע בזמינות. מלבד זאת, הוא גם מעודד עיצוב לא טוב.
Uwe סיפר שיש סטטיסטיקות של שימוש חוזר ברכיבים, ובסוף הממוצע הוא שימוש של 1.1 פעמים בשירות, וזה באמת לא משתלם וזו אחת מהסיבות לקריסת הרעיון של SOA. אומרים שלעשות משהו כתשתית זה עולה פי 9: פי 3 מאמץ למימוש יציב בכל המקרים, ושוב פי 3 כדי ליצור API טוב, תחזוקתי ומוגן. עדיף לוותר על העקרון של reusability, ובמקומו לאמץ רעיון אחר: replacability - אפשר להחליף את המימוש בצורה נקייה בכל נקודה. באופן לא מפתיע, replacability טוב מגיע איפה שיש seperation of concerns טוב.
החלטת הליבה השנייה היא לבחור את צורת התקשורת במערכת: request-replay (סינכורני) \ messaging (כמו ב-AKKA למשל) \ events וכו'. זאת החלטה חשובה שמשפיעה מאד על העיצוב, ולעיתים קרובות לא מייחסים לה חשיבות מספקת:
אחרי שקיבלנו את החלטות הליבה שלנו, הגיע הזמן למנוע משגיאות להפוך לכשלים. אבל כדי לעשות את זה עלינו לזהות ששגיאה קרתה. ניתן לבדוק את זה באחת מכמה דרכים:
אם בקשה לוקחת יותר מדי זמן, יש בעייה. עלינו לזהות שהזמן הסביר לבקשה כזאת פקע. זה נכון הן בשימוש סינכרוני והן בשימוש אסינכרוני, וקריטי יותר בסינכרוני (כי אחרת thread עלול להיתקע לנצח). רוב סביבות התכנות מכילות יכולת מובנה להתמודדות עם timeout.
במקרה שאירע timeout, ישנם כל מיני דברים שאפשר לעשות: להחזיר למשתמש שגיאה, להגיד למשתמש שהבקשה "בטיפול", להכשיל את הפעולה ולהעביר אותה לתור שיטופל אסינכרונית (ואולי לאפשר למשתמש לעקוב אחרי ההתקדמות).
הדפוס הזה הוצג לראשונה בספר "!Release It" של M. Nygard, וכנראה הוא הדפוס שמוזכר לעיתים הקרובות ביותר בהקשר ל-resilience.
הדפוס הזה הוא בעצם הרחבה של דפוס ה-timeout, שאומר שאם נכשלתי בפנייה לשירות מסויים בפעמים האחרונות, סיכוי סביר שאני אכשל שוב. לכן עדיף שאני אחסוך זמן של המשתמש ולא אנסה שוב אלא אבצע את הטיפול בכשלון באופן מיידי. פעם בכמה זמן אני אנסה שוב לראות עם השירות כן מצליח לטפל בשגיאות ורק אז אחזור לעבוד מולו.
מדובר בדפוס פשוט, ניתן לממש אותו לבד או להשתמש בתשתית כדי לחסוך את בעיות ה-thread safety (כמו לדוגמא Hystrix של Netflix שמוצעת כחלק מה-OSS שלהם. היא באה גם עם Dashboard מובנה שמציג את סטטוס ה-breakers אך לא נמצא בפיתוח יותר. Uwe גם ממליץ מאד לקרוא את הקוד של Hystrix, יש הרבה מה ללמוד ממנו על בנייה של קוד cuncurrent בצורה טובה).
הרעיון: יש מישהו שאחראי על התהליך ומוודא שהוא מסתיים. יוצרים מנהל תהליך שמוודא שהתהליך שהתחיל מהמשתמש עובר בתחנות שציפינו להן, ואם לא הוא מכריז על timeout. אפשר גם שיהיו מנהלים שונים שמבקרים תהליכים שונים בתהליך. הדפוס הזה מאפשר בקרה על ביצוע של התהליך אסינכרוני.
צריך לשים לב לא לעשות בקרה על כל הנקודות בדרך - זה הופך את התהליך האסינכרוני להתנהג כמו סינכרוני. מספיק לבדוק תחנות עיקריות בדרך. כמו כן נדרש איזון בין לקחת זמן קצר מדי ולקבל התראות שווא לבין לקחת זמן ארוך מדי ואז הזמינות יורדת.
בדיקה מתוזמנת לבדיקת בריאות של רכיבים ברשת. יש לזה שני חלקים: health check שבודק זמינות, וטרנזקציות סינכרוניות שלא משפיעות על המידע האמתי (למשל להשתמש במשתמש פיקטיבי או ישויות ספציפיות לצורך הבדיקה) שמפעילים מול הרכיבים כדי לוודא שהם מבצעים את עבודתם כהלכה.
להריץ מערכת בלי ניטור זה אמיץ. להריץ מערכת מבוזרת בלי ניטור זה טיפשי.
גם בהקשרי ניטור, כדי להקטין את ה-MTTR אנחנו צריכים לתת מקסימום מענה אוטומטי למקרים ורק ליידע אנשים שקרה אירוע, אבל בלי שתומך צריך להתערב (למשל - restart לשרתים).
זה אומר שרמות הלוג שנשתמש בהם:
הניטור יכול להיות חלק מהמערכת, זה מאפשר לו לעשות דברים יותר מורכבים. מצד שני, הוא יכול להיות חיצוני למערכת, זה עושה אותו עמיד יותר לנפילות במערכת. צריך להפעיל שיקול דעת ולבחור באופציה המתאימה לנו.
יופי, אני יודע לזהות שגיאות. עכשיו הגיע הזמן לטפל בהן כדי שלא יהפכו לכשלים. יש לנו שתי אפשרויות לעשות את זה: להתאושש מהן, או להתמודד איתן.
איך מתאוששים משגיאה שקרתה? הנה כמה אפשרויות:
לפעמים לא חייבים להתאושש מהשגיאה, ואפשר פשוט להמשיך את הפעולה בנוכחות השגיאה עד שתיפתר. גם כאן יש כמה שיטות לעשות את זה:
חוץ מאשר לזהות שגיאות ואז להתמודד איתן, אפשר גם לעשות פעילות אקטיבית למניעת תקלות.
אי אפשר למנוע ששגיאות יקרו, אפשר להקטין את ההסתברות שיקרה כשל. גם לחברות הגדולות ביותר תקלות קורות (לדוגמא, בשבוע שעבר שירותי הענן של אמזון קרסו למשך 4 שעות בגלל טעות אנוש). אבל אנחנו יכולים להקטין את ההסתברות שזה יקרה.
הדרך הכי טובה היא טיפול שגרתי - טיפול 10,000 לרכב לא מונע תקלות, אבל מקטין מאד את ההסתברות שתקלה תקרה. באותה צורה, במערכת אנחנו צריכים להשקיע זמן במניעת תקלות שאפשר למנוע, בגילוי תקלות ושגיאות שקורות ב-production ותיקונן, ומדי פעם לחזור ולאזן כמה משאבים אנחנו משקיעים בעמידות המערכת למול שאר הצרכים. כדי לעשות את זה אנחנו חייבים ליצור לעצמנו יכולת לדעת מה קורה ב-production, מתי שגיאות קורות וכו'.
עוד כמה נושאים ששווה לחשוב עליהם בהקשר לבניית מערכת עמידה:
איך מחברים יחד את כל הדברים האלה?
קודם כל, מה לא - אנחנו לא רוצים להשתמש בכל התבניות האלה. התבניות האלה הן אפשרויות, לא חובה. עלינו לבחור באלו שמתאימות לנו, וגם לא לבחור ביותר מדי - כל תבנית מוסיפה מורכבות, וכל תבנית עולה לנו כסף בסוף. יש דוגמא לְמה ש-Netflix בחרו לממש ולְ-מה ש-Erlang בחרו לממש. בדוגמא הזו למשל, Erlang הצליחו להגיע ל-5 תשיעיות של זמינות.
בשלב הזה עברנו בסדנא לתרגיל מעשי בשני שלבים. התרגיל היה מערכת של חנות אינטרנט, שיש לה הזמנות, משלוחים, וקופונים. התחלקנו ל-3 קבוצות, שכל אחת עבדה על שיטת תקשורת אחרת: סינכרונית, מסרים ואירועים. אני הייתי בקבוצה שתרגלה messaging, הנה התוצאה אליה הקבוצה שלנו הגיעה:

מסקנות עיקריות מהעבודה על התרגיל:
ישנן עוד המון תבניות.
יש מאמר (קשה) בשם building on quicksand שמדבר על מערכות מבוזרות. הרעיון בגדול הוא שכמו שבחנות קפה בהסתברות מסויימת ישכחו להביא לך את ההזמנה ואז יתנצלו, ההבטחה במערכת מבוזרת היא שאני מבטיח לעשות משהו ומבטיח לנסות ולקיים את ההבטחה.
איך גורמים לפיתוח כזה להפוך לחלק מהארגון שלנו? Uwe הציע שלושה שלבים:
בשבוע שעבר הייתה לי הזכות לקחת חלק בכנס microXchg 2017, כנס ה-Microservices המתקיים בברלין זו השנה השלישית. בכנס שמענו מגוון הרצאות בנושאים מגוונים הנוגעים לתחום מכאלה שכבר התנסו ולמדו (כמו Adrian Cockcroft, Uwe Friedrichsem, Michael Plöd ואחרים), וגם עברנו סדנאות שבהן יכולנו לתרגל חלק מהדברים יחד עם היועצים הבחירים בתחום. היה מאד מעניין ומלמד.
בימים הקרובים אני אעלה סיכומים של ההרצאות המעניינות שעברנו. למי שרוצה לפנות ישר למקור, אפשר למצוא את רוב ההרצאות בערוץ ה-YouTube של הכנס.
נקודות עיקריות שעלו בצורה מאד חזקה במהלך כל הכנס:

מדובר במאמר שכתבתי באוגוסט האחרון וכבר הופץ ברבים מפה לאוזן. אני חושב שהגיע זמנו להתפרסם ברבים.
התפיסה בה לוקחים את המערכות הגדולות בארגון שלנו ומפרקים אותם לאוסף של שירותים ומאגרי מידע היא משהו שמסתובב באוויר הארגון שלנו כבר זמן רב, בצורות שונות, אבל רק לאחרונה קורם עור וגידים. הסיבה העיקרית לכך, לטעמי, היא שבעוד שחלוקה זו נותנת תועלת רבה, היא גם מציבה דרישות שרק לאחרונה הטכנולוגיה יכולה לספק.
לא כך תכננתי, אך המאמר הזה התפתח לדבר על איך שמפתחים תוכנה, כי הנהירה בכל העולם לארכיטקטורה ממין זה נובעת באופן ישיר מהשינוי בתפיסת הפיתוח וצורת המחשבה על מהו מוצר תוכנה. תופעת לוואי של ההבנה הזאת היא אורכו של המאמר, ובעקבות כך הקורא נשאר לאורך כל המאמר בתחושה שהוא לא קורא על הנושא "שבשבילו הוא בא". כדי להפיג את הקושי הזה, הנה המבנה של המאמר:
עולם התוכנה מטבעו עובר שינויים לעיתים קרובות. ליאור בראון ניסח את "עקרון חצי הדור" (5) שמציין שמי שרוצה להישאר רלוונטי בתחום התוכנה צריך ללמוד חצי מהמקצוע מחדש בכל עשור. גם העקרונות שמנסים להשיג השתנו לאורך השנים, אבל שתי מטרות העל של עולם זה נותרו בעינן:
לגבי שתי מטרות האלה אפשר לשים לב לשני דברים חשובים: (1) הן נכונות לא רק לתוכנה, אלא לכל דבר שיש לו לקוח. (2) שתי מטרות העל האלה עומדות במתח אחת עם השנייה - לְרָצוֹת את הלקוח דורש משאבים, צמצום משאבים יכול לבוא על חשבון הלקוח. המתח הזה מגיע לקיצוניות כשמדובר במערכות מאד גדולות - הלקוח דורש הרבה מאד, והרבה פעמים כדי לרצות אותו (לפתח מערכת ענקית באיכות מלאה, שימור ידע, התאמה מלאה ללקוח וכו') אנחנו נדרשים למשאבים כל-כך רבים שלעולם לא יעמדו לרשותנו, וגם אילו עמדו לרשותנו לא היינו יודעים לנהל אותם. ההפרש בין המשאבים הנדרשים למערכות גדולות כאלה לאלה שזמינים להם, יחד עם הצורך לרצות את הלקוח בשלב השיווק, הוא אחד הגורמים המרכזיים למשבר התוכנה.
כדי ליישר קו, משבר התוכנה מדבר על זה שסדר גודל של 60% מפרויקטי התוכנה נכשלים (עמ' 9) (מקור נוסף - עמ' 5), כלומר חורגים במשאבים, לו"ז, או רידוד תכולות כדי לא לחרוג במשאבים ולו"ז.
תעשיית התוכנה מנסה להתמודד עם משבר התוכנה כבר הרבה מאד שנים בגישות שונות. גישה שתפסה בצורה מאד חזקה בשנות ה-70 היא "תפיסת המהנדסים". התפיסה הזאת הציגה גישה שדיברה על זה שמהנדס תוכנה הוא מהנדס ככל המהנדסים, ולכן עליו להשתמש באותו תהליך עבודה שעובד בצורה מוצלחת (יחסית) בעולם הבניין והחומרה כבר שנים רבות. כאשר מתכננים בניין, יש אוסף של אנשי מקצוע שעובדים על הבניין באופן טורי: איש קונספט (שמעצב את האופי של הבניין והפעילות שתקרה בו), אדריכל, מהנדס בניין, מהנדסים ספציפיים (מהנדס חשמל, מהנדס מים וכו'), קבלן - כל אחד מביא את התכנון עוד צעד מה-"מה" אל ה-"איך". אחרי זה בונים את הבניין, ואז מעבירים את הבניין אוסף של בדיקות איכות: התאמה לתוכניות, בטיחות, נגישות, כיבוי אש וכו'.
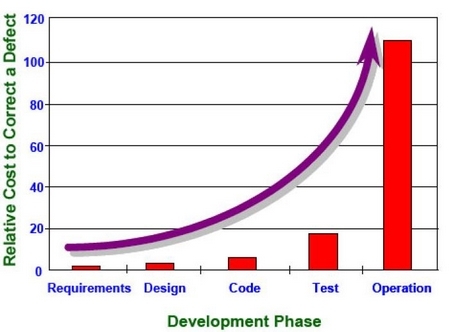
אז תפיסת המהנדסים מדברת על תהליך דומה שבו אוסף אנשי מקצוע עובדים על התוכנה באופן טורי - איש קונספט, מאפיין דרישות, מהנדס מערכת, המהנדסים הספציפיים (מאפיין פונקציונאלי, ארכיטקט, איש UX, מהנדס בדיקות), תוכניתן (אפיון טכני), אח"כ מפתחים, ובסוף מעבירים סדרת בדיקות: מילוי הדרישות, בטיחות, שימושיות, שרידות וכו'.
המתודולוגיה שהומצאה (ב-1970) כדי לממש את התפיסה הזאת היא Waterfall, על שם התהליך הטורי שמתבצע. הרעיון שהמתודולוגיה הזאת חרטה על דגלה היא הקדמת מציאת הבאגים לנקודה המוקדמת ביותר בנחל (עם הגרף האקספוננציאלי המפורסם של עלות תיקון הבאג ביחס לשלב הגילוי). השיטה הזו בוודאי שיפרה את ניצול המשאבים ובהתאם לזה העלתה את רף הגודל המקסימאלי של מערכת שאנחנו מסוגלים להרים בלי להתפשר על ריצוי הלקוח יתר על המידה.
השיטה הזו, באופן מאד צפוי, גרפה גם אהדה רבה מהמנהלים כי קל לשלוט בה, והיא נראית מצויין בגרפים: ואפשר להקים מחלקות שלמות בארגון שרק ישפרו את המדדים לראות עד כמה השיטה מתקיימת, מה האיכות שהיא מביאה, קצב ההתקדמות וכו'. במיוחד אהדו את השיטה הזאת מנהלים שבמקור באו מתחומים אחרים כמו בניין.
ברם, במבחן המציאות כעבור זמן מסויים השיטה נתקלה בקשיים משמעותיים, עד כדי כך שהרבה אנשים התחילו לחוש שהשיטה "פשטה את הרגל", והתקווה שהשיטה הזאת תפתור את משבר התוכנה נגוזה. השיטה הזאת הרימה את הרף, אבל עם האוכל בא התאבון - הדרישות עלו מהר יותר מהרף כאשר הרבה ארגונים העבירו את עיקר הפעילות שלהם להיות ממוכנת.
מעבר לזה, היו רבים שסברו שהשיטה אינה מתאימה לעולם התוכנה בגלל שהוא שונה מאד מעולמות הנדסה אחרים.
ישנם מספר מאפיינים מרכזיים שמבדלים את עולם התוכנה מעולמות הנדסה אחרים:
במהלך שנות ה-90 התפתחו אוסף של מתודולוגיות "קלות משקל" (בניגוד ל-waterfall שהיא תהליך מאד כבד). בתחילת 2001 התכנסה קבוצה של 17 מהנדסי תוכנה, כמה מהם עדיין מוכרים כמהנדסים המובילים בעולם התוכנה גם היום (כמו Martin Fowler ו-Bob Martin), כולם נציגים של המתודולוגיות קלות המשקל השונות, לשלושה ימים של ניסיון "לחשוף דרך טובה יותר לפתח תוכנה ולעזור לאחרים לעשות זאת". משלושת הימים האלה יצא ה-"Manifesto for Agile Software Development", שהצהיר כך:
"אנו חושפים דרכים טובות יותר לפיתוח תוכנה תוך עבודה ועזרה לאחרים. אלו הם ערכינו ועקרונותינו:
אנשים ויחסי גומלין על פני תהליכים וכלים
תוכנה עובדת על פני תיעוד מפורט
שיתוף פעולה עם הלקוחות על פני משא ומתן חוזי
תגובה לשינויים על פני מעקב אחרי התוכנית
כלומר, בעוד שיש ערך לפריטים בצד שמאל, אנחנו מעריכים יותר את הפריטים בצד ימין."
ניתן למצוא הסבר מלא ואת 12 העקרונות שמפרט ה-manifesto באתר וב-wikipedia. בין השאר העקרונות דיברו על תהליך איטרטיבי יחד עם הלקוחות, מסירה לעיתים קרובות, עבודה פנים-אל-פנים, מדידת תוצרים, איכות, צוותים עצמאיים (במקום הנהלה שולטת) ותחקור עצמי.
כל העקרונות האלה באו לתת מענה לאותם חוסרים של Waterfall ממקודם: עבודה איטרטיבית, מסירה לעיתים קרובות וגמישות ארגונית מאפשרות ללקוחות לשנות את דעתם ולהבין את מחיר השינוי, לזהות טעויות מהר, להקטין סיכון של שינוי ארכיטקטוני, להקטין overspeck (מגלים שהמשתמשים לא רוצים משהו בשלב מאד מוקדם, לא מתכננים מנגנונים לכל מקרה שלא יהיה ואז משתמשים בהם בדיוק פעמיים), קיצור טווח הזמנים שבו המשתמש יקבל מענה וכד'. חשוב להדגיש שהשינוי הוא לא רק באיטרציות - אלא בעיקר בהתנהלות של ארגון שהוא גמיש ומתאים את עצמו לשינויים כל הזמן.
הפיתוח ע"פ עקרונות אלה אינו מבטיח פיתוח מהיר יותר, אלא מבטיח מוצר טוב יותר, כלומר מתאים יותר ללקוחות, איכותי יותר ובזמן רלוונטי יותר, לפעמים גם על חשבון מהירות הפיתוח (כלומר מגדילים את מדדי "כמות תכולות ב-production לחודש" ו-"התאמת התכולות ללקוחות" על חשבון מדד "כמות תכולות בשנה").
ע"ב תפיסה זו התפתחו מתודולוגיות שונות כגון Scrum, Kanban ו-XP, שהמטרה של כולן היא לשים במרכז את האנשים ולא את השיטה, ולאפשר לצוותים עצמאיים לכתוב תוכנה ולהריץ אותה ל-production תוך איכות מירבית והתאמה ללקוחות. זאת כדי להשיג טוב יותר את עקרונות העל: לגרום ללקוח להיות מרוצה, ולהשקיע פחות משאבים בתהליך.
בשורה התחתונה - הסטטיסטיקה מראה שאכן בארגונים עם גמישות גבוהה (כלומר שמתנהל עם הרבה מעקרונות ה-agile) יש אחוז כשלונות נמוך יותר (עמ' 16). ובביטוי אחד: מי שגמיש מנצח.
[יש מאמר מעניין של משה דיין, שמסביר למה דויד ניצח את גוליית. בין השאר, הוא אומר: "מערכת המגן הכבידה מאוד על גלית, האיטה אותו וגם סירבלה את תנועותיו… כנגד זאת השכיל דוד לוותר על מערכת הנשק הכבדה, שהציע לו שאול, והוא בחר לנוע חשוף, אך חופשי. בעוד הפלשתי "הולך" לקראת דוד, הרי דוד "ממהר ורץ" אל המערכה (פס' מח). יתרונו של דוד היה בקלות תנועתו ויכולת התמרון שלו, והיוזמה עברה לידיו". המאמר, בשם "רוח הלוחמים", התפרסם כחלק מספר בשם "עשרים שנות קוממיות ועצמאיות, עלילות גבורה". הציטוט לקוח מתוך האתר הזה.]
מתודולוגיות הפיתוח האג'יליות, ו-SCRUM בראשן, תפסו תאוצה מאד גדולה. ובכל זאת הרבה ארגונים לא הצליחו להביא את השינוי במלואו בהתחלה, והמשיכו להתקל באותם הקשיים. למה? כי culture eats strategy for breakfast.
אג'ייל הוא צורת חשיבה. זה אומר לא רק שעושים איטרציות קצרות, אלא גם שנותנים מקום לגמישות לאורך התהליך (ואף מעודדים אותו). זה אומר שבמקום ליצור תוכניות עבודה גרנדוזיות ולמדוד התאמה אליהן, מודדים את קצב ההתקדמות ואת התפוקות למשתמשים - ואת רשימת התכולות אפשר תמיד לשנות (כמובן שתמיד יש דברים שצריך לתאם מול גופים אחרים, אבל כתפיסה). זה אומר שלא יושבים לסקרים בכל נקודה בתהליך, אלא מאפשרים לצוותים לרוץ בפיתוח ומקבלים באהבה טעויות, כי אנחנו גמישים ואפשר לתקן אותן. זה אומר ששמים דגש על גמישות בארכיטקטורה, ולא מתכננים ארכיטקטורה שתתאים לכל מה שהמערכת עלולה לעשות ב-20 שנה הקרובות. זה אומר שביטויים כמו KISS ו-YAGNI שמעודדים להעדיף קוד קצר, קריא ועונה על מה שצריך כרגע, הופכים להיות משהו מרכזי. זה אומר שההנהלה מאצילה לצוותים יותר סמכות, ומאפשרת להם להתקדם בלי לחכות להחלטות מנהלים בכל נקודה, כשההנהלה מתרכזת בקביעת יעדי הארגון ונותנת לצוותים להחליט איך מגיעים לשם.
אבל השינוי חילחל, וכיום החברות הגדולות בשוק שינו לא רק את צורת העבודה אלא גם את צורת החשיבה שלהן והתרבות שלהן - מאפשרים לצוותים לעבוד "כמו startup" ומאפשרים גמישות בפיתוח - איש ה-product עובד ישירות עם הצוותים והם מביאים כל רעיון שלו ישירות ל-production, תוך תחקור מתמיד והתמודדות עם בעיות.
עם המעבר של הארגונים לתרבות גמישה וחשיבה גמישה, להרבה עלתה השאלה - למה בעצם אני צריך איטרציות בכלל? למה להיות גמיש רק פעם בשבועיים? אני יכול להיות גמיש בכל יום. אם סיימתי תכולה, אני כבר יכול לדחוף אותה ל-production. וזה הביא את החברות למצב שבו הן דוחפות גרסא ל-production במרווחים של שניות (המצגת שהוצגה בסרטון).
בין אם פעם בשנייה או פעם בחודש, השיטה הזאת נתקלה בקשיים שנבעו מכך שכל הסביבה נבנתה לקצב איטי, ובהדרגה הטכנולוגיה בשוק התפתחה כדי להתאים לקצב המהיר החדש. לדוגמא: רכש של שרתים פיסיים הוא תהליך שלוקח הרבה מאד זמן, וזה מגביל את יכולת ההתפתחות של התוכנה שלנו (כי יכולת חדשה דורשת יותר משאבים, צריכה לשבת בנפרד, או תביא כמות גדולה של משתמשים שהמערכת לא ערוכה לקלוט). אז הומצאה הוירטואליזציה: נתקין שרתים וירטואליים, ואז אם צריך פתאום עוד שרת תמיד אפשר להרים עוד אחד על השרתים הפיסיים הקיימים. זה התפתח מאוחר יותר לענן, שבו אני משתף חומרה פיסית בין הרבה מערכות ומסוגל לחסוך הרבה וגם להגדיל (ולא פחות חשוב: להקטין) משאבים בקצב מהיר ועלות נמוכה. עוד דוגמא: לעיתים קרובות התקנה דורשת שינויי קונפיגורציה או התקנות על שרתים. כשמתקינים לעיתים מאד קרובות עלול להיווצר בלאגן גדול בסביבת ה-Production, וכל שרת יראה קצת אחרת ויגרום לבאגים. אז הומצאו ה-container-ים: אני מכין image של שרת מוכן קל משקל, ומתקין אותו על כל השרתים שלי. אם צריך לשנות משהו, אני יוצר גרסא חדשה שלו, בודק אותה ומתקין אותה. ורכיב אוטומטי יעשה התקנה הדרגתית ויוודא שכל השרתים מותקנים לגרסא החדשה בסופו של דבר.
עוד דוגמא: אני לא יכול ליצור downtime לשם התקנה לעיתים קרובות. אז הומצאו טכניקות של "התקנה חמה" שמאפשר להתקין בלי להוריד את המערכת, וגם להחזיר לאחור בקלות במקרה של כישלון. עוד דוגמא: אני לא יכול לעשות בדיקות מסירה כל הזמן. אז הומצאו טכניקות חדשות לבדיקות אוטומטיות ותהליכי אוטומציה באופן כללי.
אפשר להרחיב עוד הרבה, אבל הנקודה היא שעם שינוי התרבות בשוק התוכנה היו המון התפתחויות טכנולוגיות שכל מטרתן - לאפשר לארגונים להיות כמה שיותר גמישים.
התרבות הארגונית היא חשובה מאד אבל כדי להתקיים היא זקוקה לארכיטקטורה תומכת. ולא בכדי - יש השפעה מאד ישירה בין השניים. דוגמא לזה אפשר למצוא בחוק Conway (שקיבל אישרור ממספר מחקרים אקדמיים בשנים האחרונות) שטוען ש-"ארגונים אשר בונים מערכות… מוגבלים לייצר מערכות שהן העתקים של המבנה התקשורתי של עצמם". מחקר נוסף מראה קשר ישיר בין המורכבות הארגונית לבין איכות המוצר.
זה עובד גם בכיוון ההפוך: כדי לאפשר תרבות של מסירה לעיתים קרובות, התאמה ללקוח וכד' הארגון זקוק לארכיטקטורה שמאפשרת שינויים מהירים. אימוץ הטכנולוגיות הנזכרות מעלה הן שלב אחד, אבל זה עדיין לא השלים את המהלך.
מתוך ההבנה שהרווח של החברה תלוי ביכולת שלה להגיב מהר לשינויים, החברות בשוק התחילו לעבוד על מבנה ארכיטקטוני שונה, שמאמץ את עקרונות כתיבת התוכנה (כמו SOLID לדוגמא) לרמת הארכיטקטורה - כי הרי היכולת לכתוב קוד שקל לשנות את ההתנהגות שלו הוא הקו המנחה בכתיבת תוכנה כבר שנים רבות. העקרונות המנחים לכתיבת קוד גורמים לנו לחלק את הקוד שלנו לחלקים קטנים ככל האפשר ולהוריד את התלות בינהם, על מנת ליצור cohesion מקסימאלי ו-coupling מינימאלי:
את סט העקרונות שמאפשר לנו להשיג cohesion גבוה ו-coupling נמוך אנחנו מיישמים בארכיטקטורת הקוד שלנו כבר הרבה שנים, שהמטרה היא שיהיה קל להכניס יכולות ושינויים בקוד שלנו.
כדי לאפשר ארכיטקטורה שבה קל להכניס שינויים, לקחו את אותם העקרונות והחלו אותם על מבנה המערכת. אנחנו רוצים לשים קוד קשור ביחד וקוד לא קשור בנפרד, ולכן מחלקים את המערכת לאוסף של רכיבים קטנים שכל אחד מהם מכיל פונקציונאליות שלמה ואת כל הפונקציונאליות הזו. שיטת הארכיטקטורה הזאת זכתה לשם Microservices (או בקיצור: MSA - Micro Services Architecture).
אז מה מאפשרת MSA?
אפשר להמשיך עוד הרבה עם יתרונות של השיטה, אבל זה מכסה את הדברים העיקריים.
לא נסקור זאת במאמר הזה, אבל נגענו רק בארכיטקטורה לצד ה-backend. גם בצד ה-frontend התפתחו ארכיטקטורות וטכנולוגיות שתומכות שינויים בלתי תלויים בין רכיבים, על ידי חלוקה לרכיבים קטנים שמתקשרים דרך API גמיש (תוכנתי במקרה זה) ולא מכירים זה את זה.
כמובן, שום דבר לא בא בחינם. כשאנחנו כותבים קוד טוב שמחולק למודולים ומחלקות עם אבסטרקציות טובות, זה לעיתים בא על חשבון היכולת שלנו להבין בדיוק מה קורה בקוד - כשאנחנו קוראים אותו אנחנו רואים פעולות על כל מיני אבסטרקציות ולא יודעים מה בדיוק יעשה ה-type הקונקרטי. קוד שמפורק בצורה טובה קשה לניהול, כי הוא מפוזר על כמות גדולה של תיקיות ומודולים. בקוד גנרי עלול להיות מחיר בביצועים (בגלל שימוש ב-reflection או מבני נתונים שונים, נעילות וכו'). בקוד שמפורק בצורה טובה לפעמים אנחנו נתקלים במגבלה שקשה לנו ליצור משהו בגלל שזה יצור תלות לא בריאה, וצריך להקיף את הכל במנגנון נוסף. זה עדיין משתלם בהשוואה לאלטרנטיבה - קוד 'נקניק' שקשה להתמצא בו וכל שינוי עלול לגרום לנזק.
בצורה דומה, גם ל-MSA יש את המחיר שלה. המחיר של MSA דומה לזה של קוד איכותי:
עדיין, לטעמי לפחות (ולפי הפופולריות של MSA לא רק לטעמי), היתרונות שווים את המחיר, וככל שמדובר במערכת גדולה יותר היתרון גדול יותר. איך בכל זאת מתגברים על החסרונות? הנה כמה רעיונות:
הפתרונות לא גורמים לבעיות להיעלם, אבל מקטינים את הנפח שלהן ומשאירים את המערכת גמישה לשינויים.
איפה נמצאת עכשיו MSA מבחינת בשלות? ה-hype cycle של Gartner שם אותו בראש הגל נכון ליולי 2015 (מה שאומר שאנחנו עוד לומדים את מגבלות). סקר של Nginx מסוף 2015 מציג אחוזי חדירה גבוהים לשוק. סקר נוסף של ZeroTurnaround מיולי 2016 מציג אימוץ של MSA בכ-34% מהשוק.
צריך לזכור, MSA היא בסך הכל חיבור של הטכנולוגיות שהתפתחו (כמו ענן, אוטומציה ו-API) עם התפיסה של ארגון גמיש.
הביטוי "מאגר מידע" או "שירותי מידע" נולד הרבה לפני תפיסת ה-MSA, כשכבר לפני 7-8 שנים מהנדסים רבים בארגון הרגישו שהשיטה של ממשקים בין מערכות לא עובדת, והמידע צריך להיות נחלת הכלל.
הרעיון עבר הרבה תהפוכות ומחשבות, החל מסטנדרטים אחידים לחשיפת מידע שיחייבו את כלל המערכות, דרך DB-ים מרכזיים שישבו מעל bus-ים גדולים שדרכם אפשר יהיה לצורך ולעדכן מידע ועד ארכיטקטורות "black box" של DB גדול עם API סטנדרטי לצריכת המידע וללא לוגיקה. אבל לכל הרעיונות האלה היו חסרונות מכל מיני סוגים שנתנו לנו את התחושה שהרעיונות האלה לא מחזיקים מים, תחושה מאד מתסכלת כמי שמסתכל מהצד על ארגון תקוע שיש לו את כל מה שצריך ולא מצליח להשלים תהליכים למשתמש כי הוא לא מצליח לחבר בין המערכות.
אבל כשהגיעה MSA, התחושה הייתה שהיא מכילה בדיוק את הדברים שחיפשנו: הפרדת המידע מהאפליקציה, חלוקת המידע ליחידות פונקציונאליות נפרדות ועצמאיות יחד עם הלוגיקה שלהן, תמיכה בשינויים לא מתואמים על ידי אוסף של טכניקות תאימות לאחור ולפנים, יכולת להעלות את קצב הפיתוח על ידי התקנה מהירה ב-production עם סיכון נמוך עקב יכולת חזרה לאחור מידית, ודרגת גמישות מאד גבוהה בהתפתחות הרשת כולה.
המילה "מאגר מידע" מתייחסת למה שנקרא ב-MSA בשם "Data Service" - שירות שיודע לספק מידע ולעדכן מידע. בהתאם ל-MSA, מאגר המידע מכיל את המידע ב-storage משל עצמו (כמו DB למשל) וניתן להתקנה בנפרד לחלוטין משאר העולם. הוא עצמו עשוי להיות מורכב מאוסף של רכיבים כאלה.
אז הרעיון המסדר של מאגרי המידע הוא בדיוק זה של MSA: חלוקת העולם לרכיבים פונקציונאליים קטנים השומרים על cohesion מקסימאלי ו-coupling מינימאלי.
כדי להשיג את זה, נקבעו עקרונות למאגרים:
המטרה בתפיסת המאגרים היא לאפשר לשנות את התרבות הארגונית לתרבות גמישה, ובהתאם לשנות את הצורה שבה אנחנו מפתחים תוכנה:
חוץ מזה, למאגרים יש עוד אוסף של יתרונות לעומת הקיים בארגון שלנו כיום, מעצם זה שנוצרת הפרדה בין האפליקציה למאגר. מוביל תפיסת המאגרים בארגון שרטט את זה בשקף (שמובא כאן כטבלה):
הבעייה: TTM ארוך וחוסר רלוונטיות.
הסיבות:
|
המטרה: TTM קצר, תרומה מיידית ליכולות המשתמשים.
הפתרונות:
|
ריבוי מקורות מידע לאותו מידע
|
אמת אחת ואחריות על המידע
|
פורמט מידע קשיח
|
גמישות לשינויים וגרסאות
|
ייצוג שונה למידע באזורים שונים בארגון
|
ייצוג אחיד למידע בארגון
|
עבודה עם מונוליטים
|
פירוק לאפליקציות, שירותים ומאגרים
|
תהליך בדיקות מורכב
|
מכוון תפיסת הבדיקות החדשה
|
ההפרדה בין האפליקציה למאגר, במקרה הזה, מאפשרת סטנדרטיזציה של המאגרים וניהול המידע, ובכך להפוך את המידע להיות "נכס ארגוני" התואם לצרכי הארגון ולא לאפיון של אפליקציה ספציפית.
השינוי התרבותי הזה, יחד עם השינוי הארכיטקטוני שמאפשר אותו, צריכים להביא גם שינויים ארגוניים שיאפשרו לנו להפיק את המיטב מהתפיסה הזאת. בין השאר:
מאגרי מידע ו-MSA הם לא סוף הדרך. הם עוד אבני בניין בתהליך שהתחיל מהכרטיסיות המנוקבות, האסמבלר, השפות העיליות, OOP, ארכיטקטורת SOA ועוד הרבה שעברנו בדרך. MSA היא הטכנולוגיה הבשלה הנוכחית למימוש של גמישות ארגונית מקסימאלית. אבל המגמה ממשיכה ומתחזקת, וכבר יש טכנולוגיות שמציעות להיות השלב הבא של גמישות בתוכנה. שתי דוגמאות לטכנולוגיות כאלה:
עוד תפיסות כאלה ימשיכו ויעלו במעלה הדרך. זה יכול להיות ענן מידע (במקום DB), תקשורת מודולרית (במקום מבנה הרשת הנוכחי, SDN הוא צעד ראשון בכיוון) או אפילו מעבר להתנהגות סטטיסטית מבוססת אוסמוזה, בדומה למנגנונים בגוף האנושי.
הידיעה שהעולם ישתנה, וישתנה מהר, חייבת להיות בבסיס התרבות של ארגון שרוצה לתת מענה טוב ללקוחות שלו לאורך זמן, וחייבת להיות בבסיס הארכיטקטורה שסביבה הוא בונה את המערכת שלו, כדי שבפעם הבאה לא נצטרך שוב 10 שנים של פיתוח עם זמן ביניים מאד לא נעים כדי להתקדם בטכנולוגיה, שבסופם נגלה שאנחנו עדיין מאחור.
ושוב: מי שגמיש מנצח.
בנוסף על כל הלינקים שהופיעו במסמך, עוד כמה לינקים שימושיים:
קישור
|
לינק
|
דף עם ריכוז גדול של סטטיסטיקות
| |
מידע על התיאוריה של MSA
|
|
מידע פרקטי על השימוש ב-MSA
|
A page with a great collection of references to articles, thoughts and lectures about MSA. Probably the best you can find if you want to make a real decision or start implementing.
Netflix techbolg - Netflix opens it’s entire architecture to the public, including technics, performance issues and how they resolve them, distribution issues, tools and frameworks, etc.
|
מידע על ארכיטקטורת Consumer Driven Contract
|
|
{kind=link}