
מדובר במאמר שכתבתי באוגוסט האחרון וכבר הופץ ברבים מפה לאוזן. אני חושב שהגיע זמנו להתפרסם ברבים.
הקדמה - איך לקרוא את המאמר הזה
התפיסה בה לוקחים את המערכות הגדולות בארגון שלנו ומפרקים אותם לאוסף של שירותים ומאגרי מידע היא משהו שמסתובב באוויר הארגון שלנו כבר זמן רב, בצורות שונות, אבל רק לאחרונה קורם עור וגידים. הסיבה העיקרית לכך, לטעמי, היא שבעוד שחלוקה זו נותנת תועלת רבה, היא גם מציבה דרישות שרק לאחרונה הטכנולוגיה יכולה לספק.
לא כך תכננתי, אך המאמר הזה התפתח לדבר על איך שמפתחים תוכנה, כי הנהירה בכל העולם לארכיטקטורה ממין זה נובעת באופן ישיר מהשינוי בתפיסת הפיתוח וצורת המחשבה על מהו מוצר תוכנה. תופעת לוואי של ההבנה הזאת היא אורכו של המאמר, ובעקבות כך הקורא נשאר לאורך כל המאמר בתחושה שהוא לא קורא על הנושא "שבשבילו הוא בא". כדי להפיג את הקושי הזה, הנה המבנה של המאמר:
- רקע - עלייתו של הארגון הגמיש: פרק זה מתאר את עולם התוכנה כפי שהיה לפני 25 שנים, ואת הסיבה לעליית המתודולוגיות האג'יליות.
- משיטת ניהול לשיטת התנהלות: פרק זה מבהיר מדוע ליצור לוח SCRUM, להציג ספרינטים ועמידה ביעדי הספרינט אצל המנהל ושימוש ב-Safe בפני עצמם לא אומרים שאנחנו ארגון אג'ילי - כי אג'ייל זה מה אתה, ולא איך אתה עובד. בפרק יש גם נגיעה בטכנולוגיות שצצו בגלל ארגונים שבאמת הפכו להיות גמישים.
- שירותים מאגרי מידע: הפרק הזה עושה את הקשר לשירותים ומאגרי המידע, ומסביר שלמרות שהחזון של פירוק המערכות קיים שנים רבות, המימוש הוא לא יותר מאשר אימוץ של ארכיטקטורה גמישה.
- שינויים ארגוניים: הפרק הזה מתאר על רגל אחת את השינויים הארגוניים שצריכים לקרות יחד עם הפיכתו של הארגון לגמיש יותר.
- מה הלאה?: מי שגמיש מנצח. הארכיטקטורה הזאת משפרת את הגמישות, אך היא רק צעד אחד בדרך לארכיטקטורה גמישה עוד יותר. פרק זה מתאר בקצרה כמה מהרעיונות העולים בעולם התוכנה.
- ולבסוף עוד כמה קישורים שימושיים.
רקע - עלייתו של הארגון הגמיש
עולם התוכנה מטבעו עובר שינויים לעיתים קרובות. ליאור בראון ניסח את "עקרון חצי הדור" (5) שמציין שמי שרוצה להישאר רלוונטי בתחום התוכנה צריך ללמוד חצי מהמקצוע מחדש בכל עשור. גם העקרונות שמנסים להשיג השתנו לאורך השנים, אבל שתי מטרות העל של עולם זה נותרו בעינן:
- לגרום ללקוח להיות מרוצה - את זה אפשר להשיג ע"י מימוש כל דרישותיו, או על ידי זה שנממש יותר משהוא ציפה (גם אם הוא רצה יותר ממה שעשינו), או שהוא מרגיש שהמערכת "מבינה אותו" או שכיף לו להשתמש בה, או על ידי זה שמקלים עליו בביצוע משימה באופן משמעותי, ועוד. הגורם האחרון דומיננטי מאד בעולם שלנו, אבל בהחלט אינו היחיד.
- להשקיע מינימום משאבים - גם את זה ניתן להשיג בכל מיני דרכים. לדוגמא: העסקת עובדים טובים יותר, העסקת עובדים טובים פחות, מציאת נקודת המינימום שתרצה את הלקוח, הקטנת תקורות הפיתוח (הקדמת גילוי באגים, אוטומציה, הקטנת כמות הדיונים והתלות במנהלים, הקטנת כמות האינטגרציות הנדרשות כדי להתקדם וכד'), הקטנת תקורות התמיכה (שיפור מנגנוני ה-operation, מנגנוני ניטור מתקדמים, טיפול אוטומטי התקלות, טיפול אוטומטי בעומסים, הוזלת החומרה על ידי מחשוב ענן וכו') ועוד.
לגבי שתי מטרות האלה אפשר לשים לב לשני דברים חשובים: (1) הן נכונות לא רק לתוכנה, אלא לכל דבר שיש לו לקוח. (2) שתי מטרות העל האלה עומדות במתח אחת עם השנייה - לְרָצוֹת את הלקוח דורש משאבים, צמצום משאבים יכול לבוא על חשבון הלקוח. המתח הזה מגיע לקיצוניות כשמדובר במערכות מאד גדולות - הלקוח דורש הרבה מאד, והרבה פעמים כדי לרצות אותו (לפתח מערכת ענקית באיכות מלאה, שימור ידע, התאמה מלאה ללקוח וכו') אנחנו נדרשים למשאבים כל-כך רבים שלעולם לא יעמדו לרשותנו, וגם אילו עמדו לרשותנו לא היינו יודעים לנהל אותם. ההפרש בין המשאבים הנדרשים למערכות גדולות כאלה לאלה שזמינים להם, יחד עם הצורך לרצות את הלקוח בשלב השיווק, הוא אחד הגורמים המרכזיים למשבר התוכנה.
כדי ליישר קו, משבר התוכנה מדבר על זה שסדר גודל של 60% מפרויקטי התוכנה נכשלים (עמ' 9) (מקור נוסף - עמ' 5), כלומר חורגים במשאבים, לו"ז, או רידוד תכולות כדי לא לחרוג במשאבים ולו"ז.
תעשיית התוכנה מנסה להתמודד עם משבר התוכנה כבר הרבה מאד שנים בגישות שונות. גישה שתפסה בצורה מאד חזקה בשנות ה-70 היא "תפיסת המהנדסים". התפיסה הזאת הציגה גישה שדיברה על זה שמהנדס תוכנה הוא מהנדס ככל המהנדסים, ולכן עליו להשתמש באותו תהליך עבודה שעובד בצורה מוצלחת (יחסית) בעולם הבניין והחומרה כבר שנים רבות. כאשר מתכננים בניין, יש אוסף של אנשי מקצוע שעובדים על הבניין באופן טורי: איש קונספט (שמעצב את האופי של הבניין והפעילות שתקרה בו), אדריכל, מהנדס בניין, מהנדסים ספציפיים (מהנדס חשמל, מהנדס מים וכו'), קבלן - כל אחד מביא את התכנון עוד צעד מה-"מה" אל ה-"איך". אחרי זה בונים את הבניין, ואז מעבירים את הבניין אוסף של בדיקות איכות: התאמה לתוכניות, בטיחות, נגישות, כיבוי אש וכו'.
אז תפיסת המהנדסים מדברת על תהליך דומה שבו אוסף אנשי מקצוע עובדים על התוכנה באופן טורי - איש קונספט, מאפיין דרישות, מהנדס מערכת, המהנדסים הספציפיים (מאפיין פונקציונאלי, ארכיטקט, איש UX, מהנדס בדיקות), תוכניתן (אפיון טכני), אח"כ מפתחים, ובסוף מעבירים סדרת בדיקות: מילוי הדרישות, בטיחות, שימושיות, שרידות וכו'.
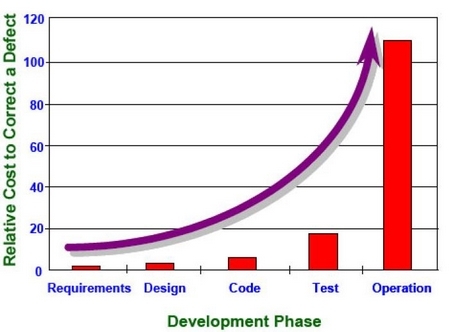
המתודולוגיה שהומצאה (ב-1970) כדי לממש את התפיסה הזאת היא Waterfall, על שם התהליך הטורי שמתבצע. הרעיון שהמתודולוגיה הזאת חרטה על דגלה היא הקדמת מציאת הבאגים לנקודה המוקדמת ביותר בנחל (עם הגרף האקספוננציאלי המפורסם של עלות תיקון הבאג ביחס לשלב הגילוי). השיטה הזו בוודאי שיפרה את ניצול המשאבים ובהתאם לזה העלתה את רף הגודל המקסימאלי של מערכת שאנחנו מסוגלים להרים בלי להתפשר על ריצוי הלקוח יתר על המידה.
{kind=link}
השיטה הזו, באופן מאד צפוי, גרפה גם אהדה רבה מהמנהלים כי קל לשלוט בה, והיא נראית מצויין בגרפים: ואפשר להקים מחלקות שלמות בארגון שרק ישפרו את המדדים לראות עד כמה השיטה מתקיימת, מה האיכות שהיא מביאה, קצב ההתקדמות וכו'. במיוחד אהדו את השיטה הזאת מנהלים שבמקור באו מתחומים אחרים כמו בניין.
ברם, במבחן המציאות כעבור זמן מסויים השיטה נתקלה בקשיים משמעותיים, עד כדי כך שהרבה אנשים התחילו לחוש שהשיטה "פשטה את הרגל", והתקווה שהשיטה הזאת תפתור את משבר התוכנה נגוזה. השיטה הזאת הרימה את הרף, אבל עם האוכל בא התאבון - הדרישות עלו מהר יותר מהרף כאשר הרבה ארגונים העבירו את עיקר הפעילות שלהם להיות ממוכנת.
מעבר לזה, היו רבים שסברו שהשיטה אינה מתאימה לעולם התוכנה בגלל שהוא שונה מאד מעולמות הנדסה אחרים.
ישנם מספר מאפיינים מרכזיים שמבדלים את עולם התוכנה מעולמות הנדסה אחרים:
- מחיר הטעות - מחיר הטעות (כלומר השינוי) בתוכנה נמוך משמעותית מהמחיר בעולם הפיסי. יש לזה מספר השלכות:
- המשתמשים מרשים לעצמם לשנות את דעתם.
- בהערכות נכונה אנחנו יכולים לאפשר למשתמשים לשנות את דעתם.
- ככל שה-cycle של דרישה->מבצוע ארוך יותר, מחיר השינוי עולה.
- בהנחה שהיכולת לשנות היא בעלת ערך מבצעי שלעצמה, חברות רבות חרטו על דגלן את תפיסת "embrace the change" או אפילו "fail fast + embrace failure" - במקום לתכנן המון ולפחד מטעויות, עשה מה שצריך וצור מנגנונים שמאפשרים לך לזהות טעויות מהר, לתקן טעויות מהר, ולשתף טעויות ומסקנות מהן בארגון.
- התיישנות - תוכנה מתיישנת מהר. כשבונים בניין יש תקופת בנייה מוגדרת ואח"כ שימוש שוטף ללא בנייה (מלבד שיפוצים מדי פעם ותחזוקה שוטפת) לתקופה ארוכה הרבה יותר. בניין בנוי כהלכה יכול לעמוד מאות שנים.
תוכנה נמצאת לרוב בפיתוח שוטף, ולכן צוברת בלאי מהר. בנוסף, הטכנולוגיה מתקדמת מהר מאד וגורמת להתיישנות - כלים/תשתיות בלי תמיכה ופיתוח, מראה מיושן, חוסר תמיכה בכלים הטובים יותר שקיימים, חוסר תאימות למערכת הפעלה/חומרה, התמעטות משתמשים בעולם (ולכן מענה בפורומים) וכו'. - זה מחייב לעשות שינויי ארכ' וקוד מרחיבים מעת לעת כדי לשמור על חדשנות. זה מחייב ארכיטקטורה שמאפשרת שינוי, ומעלה את העלות היחסית של תכנון ארוך.
- דינאמיות - רכב או בניין הם מרחב עבודה, אבל מה שעושים בתוכו משתנה בקלות. לא היינו קונים בית שבו השולחן והספה ייצוקים מבטון ואי אפשר להזיז אותם אם אנחנו רוצים לעשות משהו מיוחד, או שיש בו מקום בדיוק למה שיש לנו ואי אפשר להכניס עוד גרב, כי השימוש שלנו בבניין משתנה לאורך זמן.
תוכנה, לעומת זאת, היא כלי יום יומי של עבודה. היא צריכה להיות דינאמית ולשנות את התנהגותה בעקבות השתנות המשתמשים ומשימותיהם בטווחי זמן קצרים. - מסמכים - המסמכים בבנייה הם מאד תחומים ופורמאליים - תוכניות בנייה. תוכניות הבנייה ברורות לחלוטין לכל מי שמסתכל עליהן ועונות לסטנדרטים מאד חזקים, כך שהקבלן שבונה את הבניין יכול להסתכל על התוכניות בלבד ולבנות את הבניין במדוייק, ואחרי כל צעד למדוד בפירוט שאכן מה שהוא עשה תואם את התוכניות. כמו כן, התוכניות הן פורמאליות מספיק כך שמחשב יכול להריץ אותן - להציג מודל תלת מימדי שבו הלקוח יכול להסתובב ולראות אם אכן הבניין מתאים לצרכיו.
בתוכנה כמות הפרטים גדולה בהרבה, והסטנדרטים הם הרבה פחות ברורים ומשתנים מהר. כמות האפשרויות גדולה בהרבה, ויש הרבה מקרים שלא ניתן לכסות באפיון באופן מלא - אפיון של 100% לוקח כמעט אותו זמן של יצירת התוכנה. כמו כן יש יכולת מאד מוגבלת להציג למשתמש מודל (מלבד אחד שהוא מאד מופשט ושונה ממה שיתקבל בסוף) כי בניית מודל מלא שקולה לכתיבת התוכנה כולה.
המסמכים הרבים שנדרשים לכתוב בתהליך Waterfall הם בסוף בעלי תועלת פחותה מבתחומים אחרים ועדיין גוזלים לא פחות זמן. יש לזכור בנוסף שתוכניות הבניין כוללות רק מבנה, בעוד שההתנהגות הפונקציונאלית משתנה כל הזמן, בעוד שמסמכי עיצוב תוכנה כוללים גם את ההתנהגות הפונקציונאלית.
במהלך שנות ה-90 התפתחו אוסף של מתודולוגיות "קלות משקל" (בניגוד ל-waterfall שהיא תהליך מאד כבד). בתחילת 2001 התכנסה קבוצה של 17 מהנדסי תוכנה, כמה מהם עדיין מוכרים כמהנדסים המובילים בעולם התוכנה גם היום (כמו Martin Fowler ו-Bob Martin), כולם נציגים של המתודולוגיות קלות המשקל השונות, לשלושה ימים של ניסיון "לחשוף דרך טובה יותר לפתח תוכנה ולעזור לאחרים לעשות זאת". משלושת הימים האלה יצא ה-"Manifesto for Agile Software Development", שהצהיר כך:
"אנו חושפים דרכים טובות יותר לפיתוח תוכנה תוך עבודה ועזרה לאחרים. אלו הם ערכינו ועקרונותינו:
אנשים ויחסי גומלין על פני תהליכים וכלים
תוכנה עובדת על פני תיעוד מפורט
שיתוף פעולה עם הלקוחות על פני משא ומתן חוזי
תגובה לשינויים על פני מעקב אחרי התוכנית
כלומר, בעוד שיש ערך לפריטים בצד שמאל, אנחנו מעריכים יותר את הפריטים בצד ימין."
ניתן למצוא הסבר מלא ואת 12 העקרונות שמפרט ה-manifesto באתר וב-wikipedia. בין השאר העקרונות דיברו על תהליך איטרטיבי יחד עם הלקוחות, מסירה לעיתים קרובות, עבודה פנים-אל-פנים, מדידת תוצרים, איכות, צוותים עצמאיים (במקום הנהלה שולטת) ותחקור עצמי.
כל העקרונות האלה באו לתת מענה לאותם חוסרים של Waterfall ממקודם: עבודה איטרטיבית, מסירה לעיתים קרובות וגמישות ארגונית מאפשרות ללקוחות לשנות את דעתם ולהבין את מחיר השינוי, לזהות טעויות מהר, להקטין סיכון של שינוי ארכיטקטוני, להקטין overspeck (מגלים שהמשתמשים לא רוצים משהו בשלב מאד מוקדם, לא מתכננים מנגנונים לכל מקרה שלא יהיה ואז משתמשים בהם בדיוק פעמיים), קיצור טווח הזמנים שבו המשתמש יקבל מענה וכד'. חשוב להדגיש שהשינוי הוא לא רק באיטרציות - אלא בעיקר בהתנהלות של ארגון שהוא גמיש ומתאים את עצמו לשינויים כל הזמן.
הפיתוח ע"פ עקרונות אלה אינו מבטיח פיתוח מהיר יותר, אלא מבטיח מוצר טוב יותר, כלומר מתאים יותר ללקוחות, איכותי יותר ובזמן רלוונטי יותר, לפעמים גם על חשבון מהירות הפיתוח (כלומר מגדילים את מדדי "כמות תכולות ב-production לחודש" ו-"התאמת התכולות ללקוחות" על חשבון מדד "כמות תכולות בשנה").
ע"ב תפיסה זו התפתחו מתודולוגיות שונות כגון Scrum, Kanban ו-XP, שהמטרה של כולן היא לשים במרכז את האנשים ולא את השיטה, ולאפשר לצוותים עצמאיים לכתוב תוכנה ולהריץ אותה ל-production תוך איכות מירבית והתאמה ללקוחות. זאת כדי להשיג טוב יותר את עקרונות העל: לגרום ללקוח להיות מרוצה, ולהשקיע פחות משאבים בתהליך.
בשורה התחתונה - הסטטיסטיקה מראה שאכן בארגונים עם גמישות גבוהה (כלומר שמתנהל עם הרבה מעקרונות ה-agile) יש אחוז כשלונות נמוך יותר (עמ' 16). ובביטוי אחד: מי שגמיש מנצח.
[יש מאמר מעניין של משה דיין, שמסביר למה דויד ניצח את גוליית. בין השאר, הוא אומר: "מערכת המגן הכבידה מאוד על גלית, האיטה אותו וגם סירבלה את תנועותיו… כנגד זאת השכיל דוד לוותר על מערכת הנשק הכבדה, שהציע לו שאול, והוא בחר לנוע חשוף, אך חופשי. בעוד הפלשתי "הולך" לקראת דוד, הרי דוד "ממהר ורץ" אל המערכה (פס' מח). יתרונו של דוד היה בקלות תנועתו ויכולת התמרון שלו, והיוזמה עברה לידיו". המאמר, בשם "רוח הלוחמים", התפרסם כחלק מספר בשם "עשרים שנות קוממיות ועצמאיות, עלילות גבורה". הציטוט לקוח מתוך האתר הזה.]
משיטת ניהול לשיטת התנהלות
מתודולוגיות הפיתוח האג'יליות, ו-SCRUM בראשן, תפסו תאוצה מאד גדולה. ובכל זאת הרבה ארגונים לא הצליחו להביא את השינוי במלואו בהתחלה, והמשיכו להתקל באותם הקשיים. למה? כי culture eats strategy for breakfast.
אג'ייל הוא צורת חשיבה. זה אומר לא רק שעושים איטרציות קצרות, אלא גם שנותנים מקום לגמישות לאורך התהליך (ואף מעודדים אותו). זה אומר שבמקום ליצור תוכניות עבודה גרנדוזיות ולמדוד התאמה אליהן, מודדים את קצב ההתקדמות ואת התפוקות למשתמשים - ואת רשימת התכולות אפשר תמיד לשנות (כמובן שתמיד יש דברים שצריך לתאם מול גופים אחרים, אבל כתפיסה). זה אומר שלא יושבים לסקרים בכל נקודה בתהליך, אלא מאפשרים לצוותים לרוץ בפיתוח ומקבלים באהבה טעויות, כי אנחנו גמישים ואפשר לתקן אותן. זה אומר ששמים דגש על גמישות בארכיטקטורה, ולא מתכננים ארכיטקטורה שתתאים לכל מה שהמערכת עלולה לעשות ב-20 שנה הקרובות. זה אומר שביטויים כמו KISS ו-YAGNI שמעודדים להעדיף קוד קצר, קריא ועונה על מה שצריך כרגע, הופכים להיות משהו מרכזי. זה אומר שההנהלה מאצילה לצוותים יותר סמכות, ומאפשרת להם להתקדם בלי לחכות להחלטות מנהלים בכל נקודה, כשההנהלה מתרכזת בקביעת יעדי הארגון ונותנת לצוותים להחליט איך מגיעים לשם.
אבל השינוי חילחל, וכיום החברות הגדולות בשוק שינו לא רק את צורת העבודה אלא גם את צורת החשיבה שלהן והתרבות שלהן - מאפשרים לצוותים לעבוד "כמו startup" ומאפשרים גמישות בפיתוח - איש ה-product עובד ישירות עם הצוותים והם מביאים כל רעיון שלו ישירות ל-production, תוך תחקור מתמיד והתמודדות עם בעיות.
עם המעבר של הארגונים לתרבות גמישה וחשיבה גמישה, להרבה עלתה השאלה - למה בעצם אני צריך איטרציות בכלל? למה להיות גמיש רק פעם בשבועיים? אני יכול להיות גמיש בכל יום. אם סיימתי תכולה, אני כבר יכול לדחוף אותה ל-production. וזה הביא את החברות למצב שבו הן דוחפות גרסא ל-production במרווחים של שניות (המצגת שהוצגה בסרטון).
בין אם פעם בשנייה או פעם בחודש, השיטה הזאת נתקלה בקשיים שנבעו מכך שכל הסביבה נבנתה לקצב איטי, ובהדרגה הטכנולוגיה בשוק התפתחה כדי להתאים לקצב המהיר החדש. לדוגמא: רכש של שרתים פיסיים הוא תהליך שלוקח הרבה מאד זמן, וזה מגביל את יכולת ההתפתחות של התוכנה שלנו (כי יכולת חדשה דורשת יותר משאבים, צריכה לשבת בנפרד, או תביא כמות גדולה של משתמשים שהמערכת לא ערוכה לקלוט). אז הומצאה הוירטואליזציה: נתקין שרתים וירטואליים, ואז אם צריך פתאום עוד שרת תמיד אפשר להרים עוד אחד על השרתים הפיסיים הקיימים. זה התפתח מאוחר יותר לענן, שבו אני משתף חומרה פיסית בין הרבה מערכות ומסוגל לחסוך הרבה וגם להגדיל (ולא פחות חשוב: להקטין) משאבים בקצב מהיר ועלות נמוכה. עוד דוגמא: לעיתים קרובות התקנה דורשת שינויי קונפיגורציה או התקנות על שרתים. כשמתקינים לעיתים מאד קרובות עלול להיווצר בלאגן גדול בסביבת ה-Production, וכל שרת יראה קצת אחרת ויגרום לבאגים. אז הומצאו ה-container-ים: אני מכין image של שרת מוכן קל משקל, ומתקין אותו על כל השרתים שלי. אם צריך לשנות משהו, אני יוצר גרסא חדשה שלו, בודק אותה ומתקין אותה. ורכיב אוטומטי יעשה התקנה הדרגתית ויוודא שכל השרתים מותקנים לגרסא החדשה בסופו של דבר.
עוד דוגמא: אני לא יכול ליצור downtime לשם התקנה לעיתים קרובות. אז הומצאו טכניקות של "התקנה חמה" שמאפשר להתקין בלי להוריד את המערכת, וגם להחזיר לאחור בקלות במקרה של כישלון. עוד דוגמא: אני לא יכול לעשות בדיקות מסירה כל הזמן. אז הומצאו טכניקות חדשות לבדיקות אוטומטיות ותהליכי אוטומציה באופן כללי.
אפשר להרחיב עוד הרבה, אבל הנקודה היא שעם שינוי התרבות בשוק התוכנה היו המון התפתחויות טכנולוגיות שכל מטרתן - לאפשר לארגונים להיות כמה שיותר גמישים.
ארכיטקטורה תומכת ארגון גמיש
התרבות הארגונית היא חשובה מאד אבל כדי להתקיים היא זקוקה לארכיטקטורה תומכת. ולא בכדי - יש השפעה מאד ישירה בין השניים. דוגמא לזה אפשר למצוא בחוק Conway (שקיבל אישרור ממספר מחקרים אקדמיים בשנים האחרונות) שטוען ש-"ארגונים אשר בונים מערכות… מוגבלים לייצר מערכות שהן העתקים של המבנה התקשורתי של עצמם". מחקר נוסף מראה קשר ישיר בין המורכבות הארגונית לבין איכות המוצר.
זה עובד גם בכיוון ההפוך: כדי לאפשר תרבות של מסירה לעיתים קרובות, התאמה ללקוח וכד' הארגון זקוק לארכיטקטורה שמאפשרת שינויים מהירים. אימוץ הטכנולוגיות הנזכרות מעלה הן שלב אחד, אבל זה עדיין לא השלים את המהלך.
מתוך ההבנה שהרווח של החברה תלוי ביכולת שלה להגיב מהר לשינויים, החברות בשוק התחילו לעבוד על מבנה ארכיטקטוני שונה, שמאמץ את עקרונות כתיבת התוכנה (כמו SOLID לדוגמא) לרמת הארכיטקטורה - כי הרי היכולת לכתוב קוד שקל לשנות את ההתנהגות שלו הוא הקו המנחה בכתיבת תוכנה כבר שנים רבות. העקרונות המנחים לכתיבת קוד גורמים לנו לחלק את הקוד שלנו לחלקים קטנים ככל האפשר ולהוריד את התלות בינהם, על מנת ליצור cohesion מקסימאלי ו-coupling מינימאלי:
- Cohesion גבוה אומר שלמודול יש פונקציונאליות אחת, כלומר שקוד לא קשור יושב בנפרד. נגיד שאני עובד ב-Amazon, וצריך להוסיף feature לתהליך ההזמנה. האם אני עלול לגרום לבאג בתהליך של משלוח? אם כן, זה כנראה אומר שיש לי cohesion נמוך מדי, כי יש לי קוד שעושה הזמנות וקוד שעושה משלוחים באותו מקום.
- Coupling נמוך אומר שפונקציונאליות שלמה יושבת במודול אחד, כלומר שקוד קשור יושב ביחד. אם ביקשו ממני להוסיף feature לתהליך ההזמנה ואני צריך לגעת בשני מודולים, כנראה שיש לי coupling גבוה מדי.
את סט העקרונות שמאפשר לנו להשיג cohesion גבוה ו-coupling נמוך אנחנו מיישמים בארכיטקטורת הקוד שלנו כבר הרבה שנים, שהמטרה היא שיהיה קל להכניס יכולות ושינויים בקוד שלנו.
כדי לאפשר ארכיטקטורה שבה קל להכניס שינויים, לקחו את אותם העקרונות והחלו אותם על מבנה המערכת. אנחנו רוצים לשים קוד קשור ביחד וקוד לא קשור בנפרד, ולכן מחלקים את המערכת לאוסף של רכיבים קטנים שכל אחד מהם מכיל פונקציונאליות שלמה ואת כל הפונקציונאליות הזו. שיטת הארכיטקטורה הזאת זכתה לשם Microservices (או בקיצור: MSA - Micro Services Architecture).
אז מה מאפשרת MSA?
- קודם כל, כמו בקוד: אם רוצים להכניס feature, לרוב נצטרך לגעת רק במקום אחד, שמכיל רק פונציונאליות אחת. זה אומר שהסיכוי שנכניס באג במקום אחר או בפונקציונאליות אחרת הוא נמוך מאד. וזה אומר שמספיק להתעמק בבדיקה לפונקציונאליות שנגענו בה.
- "לגעת" במקום אחד זה לא רק לשנות קוד, גם התקנה היא נגיעה. כ-80% מהתקלות בתוכנה קורות לאחר התקנה. ע"י צמצום האזור שנוגעים בו, ניתן לצמצם משמעותית את כמות הבאגים.
- גם כמו בקוד: קוד שממודל טוב, עם מעט תלויות ועם dependency inversion, מאפשר לנו לשנות את הארכיטקטורה של התוכנה (ואף לבנות תוכנה נוספת) ולהמשיך להשתמש בקוד הקיים, על ידי שינוי של רכיבים ספציפיים והקוד המקשר בלבד. עם process-ים, ניתן גם כן לשנות את ארכיטקטורת המערכת וליצור מערכות נוספות על ידי שינוי מעט מאד קוד ואת הקישור (routing) בלי לגעת ברכיבים קיימים.
- היכולת שלנו לשנות ולהתקין קטע קוד ממוקד בלי לגעת בשאר המערכת מאפשרת לנו גם להתמודד טוב יותר עם תקלות. אם נמצאה תקלה בגרסא מסויימת, ניתן להתקין תיקון מקומי. יותר מזה, קל מאד לחזור לגרסא קודמת ולהתקין את הגרסא באופן הדרגתי.
- בשימוש ב-API לתקשורת בין רכיבים, יש לנו הרבה יותר יכולות של שמירת תאימות לאחור מאשר בשימוש ב-interface תכנותי. API גם נוטה באופן טבעי להיות מתועד טוב יותר.
- תקלה בשרת מסויים, בין אם תוכנה או חומרה, תגרום לפגיעה משמעותית במונוליט אבל לפגיעה יחסית זניחה ב-process קטן שהוא אחד מיני רבים במערכת.
- ניתן לחשוף feature מסויים באופן הדרגתי - להתקין instance אחד של הגרסא החדשה, ולהפנות רק חלק מהבקשות מהשרת אל ה-instance הזה.
- ניתן להפריד את ה-lifecycle של היחידות הפונקציונאליות ולנהל אותן בנפרד. זה יתרון מאד גדול, כי מחקרים מראים שאחוז ההצלחה בפרוייקטים קטנים הוא גדול משמעותית מזה של פרוייקטים גדולים (מאמר של גרטנר שמציג 50% יותר הצלחה בפרויקטים קטנים, מאמר של CHAOS שמציג הפרש עוד יותר קיצוני (עמ' 8)). חלוקה לפרוייקטים קטנים עם תלות מינימאלית משפרת את סיכויי ההצלחה (זאת גם ההמלצה במאמר של גרטנר).
- בגדול כמות המצבים שמערכת יכולה להיות בהם היא אקספוננציאלית בכמות הזיכרון שהיא משתמשת. כשלוקחים רכיב קטן עם מרחב זיכרון נפרד, כמות המצבים היא לוגריתמית לעומת של מערכת גדולה ולכן ניתן לכסות בבדיקות פשוטות יותר כמות מצבים גדולה הרבה יותר. יותר מזה, רוב היחידות הפונקציונאליות לא צריכות להחזיק state בעצמן (אלא משתמשות ב-state של יחידה פונקציונאלית אחרת) ולכן כמות המצבים בהן קטן עוד יותר באופן ניכר.
- כאשר מערכת רצה ב-process אחד, זה גורם לתלות נוספת בן הרכיבים - תלות טכנולוגית. כאשר מפרקים מערכת לרכיבים נפרדים, הם לא חייבים להיות באותה טכנולוגיה. זה מאפשר לבחור את הטכנולוגיה הנכונה לצורך, ויותר חשוב מזה - כאשר מחליטים להחליף טכנולוגיה אפשר לעשות שידרוג הדרגתי.
אפשר להמשיך עוד הרבה עם יתרונות של השיטה, אבל זה מכסה את הדברים העיקריים.
לא נסקור זאת במאמר הזה, אבל נגענו רק בארכיטקטורה לצד ה-backend. גם בצד ה-frontend התפתחו ארכיטקטורות וטכנולוגיות שתומכות שינויים בלתי תלויים בין רכיבים, על ידי חלוקה לרכיבים קטנים שמתקשרים דרך API גמיש (תוכנתי במקרה זה) ולא מכירים זה את זה.
כמובן, שום דבר לא בא בחינם. כשאנחנו כותבים קוד טוב שמחולק למודולים ומחלקות עם אבסטרקציות טובות, זה לעיתים בא על חשבון היכולת שלנו להבין בדיוק מה קורה בקוד - כשאנחנו קוראים אותו אנחנו רואים פעולות על כל מיני אבסטרקציות ולא יודעים מה בדיוק יעשה ה-type הקונקרטי. קוד שמפורק בצורה טובה קשה לניהול, כי הוא מפוזר על כמות גדולה של תיקיות ומודולים. בקוד גנרי עלול להיות מחיר בביצועים (בגלל שימוש ב-reflection או מבני נתונים שונים, נעילות וכו'). בקוד שמפורק בצורה טובה לפעמים אנחנו נתקלים במגבלה שקשה לנו ליצור משהו בגלל שזה יצור תלות לא בריאה, וצריך להקיף את הכל במנגנון נוסף. זה עדיין משתלם בהשוואה לאלטרנטיבה - קוד 'נקניק' שקשה להתמצא בו וכל שינוי עלול לגרום לנזק.
בצורה דומה, גם ל-MSA יש את המחיר שלה. המחיר של MSA דומה לזה של קוד איכותי:
- הקוד מחולק על פני תהליכים שונים, קשה לראות במבט אחד תהליך שלם וקשה לדבג תהליך שלם.
- כדי למנוע תלויות, צריך להפריד את המידע ולהתבסס רק על API. זה אומר שיש ביזור בשמירת המידע, וצריך להתמודד איתו אחרת מאשר עבודה על DB יחיד.
- המעבר לשימוש ב-API מחייב תקשורת, שמטבעה היא איטית יותר מאשר קריאה לפונקציה.
- ניהול צי שרתים הוא קשה הרבה יותר מניהול שרתים ספורים, ודורש עבודת DevOps איכותית ועם אוטומציה. [בהקשר הזה, יש אנלוגיה מקובלת שמדברת על "שרתים הם בקר, לא חיות מחמד". אפשר לקרוא כאן וכאן, וגם בראיון המצויין (כמו תמיד) על MSA עם אדריאן קוקרופט, ארכיטקט נטפליקס לשעבר ו-VP ארכיטקטורה בשירותי הענן של אמזון בהווה]
עדיין, לטעמי לפחות (ולפי הפופולריות של MSA לא רק לטעמי), היתרונות שווים את המחיר, וככל שמדובר במערכת גדולה יותר היתרון גדול יותר. איך בכל זאת מתגברים על החסרונות? הנה כמה רעיונות:
- החלוקה לחלקים קטנים מאפשרת לנו לעקוב אחרי מה שקורה בפועל במערכת מבחוץ, וזה מאפשר לנו ליצור ויזואלוזיציה של דרכה של הודעה, החל משליפת כל השלבים שעברה הודעה ספציפית (שזה קל מאד ע"ב ELK למשל) ועד כלים שמציגים את התנועה במערכת, כמו למשל Appdynamics או חבילת הכלים של Netflix.
- כדי להתמודד עם ביזור בשמירת המידע, משתמשים ב-eventual consistency (מה שבכל מקרה הכרחי אם רוצים יכולת scaling יחד עם זמינות גבוהה - ראה CAP Theorem).
- עבודה עם תקשורת: החלוקה מאפשרת לנו לשפר ביצועים במקום אחר - Outscale קל רק בצווארי הבקבוק, מה שגורם ל-scaling לעבוד הרבה יותר טוב. זה מאפשר מקבול בין שרתים של הפעולות. ובמקרה הכי גרוע, תמיד אפשר לשבור את העקרונות כשיש בעיה, וב-MSA אפשר לשבור אותם בצורה מאד מקומית ומתוחמת.
- ניהול צי שרתים: בגלל הנפחים של התעבורה, החברות הגדולות (וגם לא כל-כך גדולות) מנהלות ציים של עשרות אלפי שרתים. לכן יש המון המון המון המון כלים לויזואליזציה, ניטור ותחזוקה של הרשת.
הפתרונות לא גורמים לבעיות להיעלם, אבל מקטינים את הנפח שלהן ומשאירים את המערכת גמישה לשינויים.
איפה נמצאת עכשיו MSA מבחינת בשלות? ה-hype cycle של Gartner שם אותו בראש הגל נכון ליולי 2015 (מה שאומר שאנחנו עוד לומדים את מגבלות). סקר של Nginx מסוף 2015 מציג אחוזי חדירה גבוהים לשוק. סקר נוסף של ZeroTurnaround מיולי 2016 מציג אימוץ של MSA בכ-34% מהשוק.
צריך לזכור, MSA היא בסך הכל חיבור של הטכנולוגיות שהתפתחו (כמו ענן, אוטומציה ו-API) עם התפיסה של ארגון גמיש.
מאגרי מידע ושירותים
הביטוי "מאגר מידע" או "שירותי מידע" נולד הרבה לפני תפיסת ה-MSA, כשכבר לפני 7-8 שנים מהנדסים רבים בארגון הרגישו שהשיטה של ממשקים בין מערכות לא עובדת, והמידע צריך להיות נחלת הכלל.
הרעיון עבר הרבה תהפוכות ומחשבות, החל מסטנדרטים אחידים לחשיפת מידע שיחייבו את כלל המערכות, דרך DB-ים מרכזיים שישבו מעל bus-ים גדולים שדרכם אפשר יהיה לצורך ולעדכן מידע ועד ארכיטקטורות "black box" של DB גדול עם API סטנדרטי לצריכת המידע וללא לוגיקה. אבל לכל הרעיונות האלה היו חסרונות מכל מיני סוגים שנתנו לנו את התחושה שהרעיונות האלה לא מחזיקים מים, תחושה מאד מתסכלת כמי שמסתכל מהצד על ארגון תקוע שיש לו את כל מה שצריך ולא מצליח להשלים תהליכים למשתמש כי הוא לא מצליח לחבר בין המערכות.
אבל כשהגיעה MSA, התחושה הייתה שהיא מכילה בדיוק את הדברים שחיפשנו: הפרדת המידע מהאפליקציה, חלוקת המידע ליחידות פונקציונאליות נפרדות ועצמאיות יחד עם הלוגיקה שלהן, תמיכה בשינויים לא מתואמים על ידי אוסף של טכניקות תאימות לאחור ולפנים, יכולת להעלות את קצב הפיתוח על ידי התקנה מהירה ב-production עם סיכון נמוך עקב יכולת חזרה לאחור מידית, ודרגת גמישות מאד גבוהה בהתפתחות הרשת כולה.
המילה "מאגר מידע" מתייחסת למה שנקרא ב-MSA בשם "Data Service" - שירות שיודע לספק מידע ולעדכן מידע. בהתאם ל-MSA, מאגר המידע מכיל את המידע ב-storage משל עצמו (כמו DB למשל) וניתן להתקנה בנפרד לחלוטין משאר העולם. הוא עצמו עשוי להיות מורכב מאוסף של רכיבים כאלה.
אז הרעיון המסדר של מאגרי המידע הוא בדיוק זה של MSA: חלוקת העולם לרכיבים פונקציונאליים קטנים השומרים על cohesion מקסימאלי ו-coupling מינימאלי.
כדי להשיג את זה, נקבעו עקרונות למאגרים:
- אם לישויות יש לוגיקה עיקרית משותפת, נשים אותם ביחד כדי להשיג cohesion גבוה - אם נרצה לעשות שינוי בלוגיקה, לא נפגע בלוגיקה של ישויות אחרות.
- אם לישויות יש מעט במשותף, נשים אותם בנפרד כדי להשיג coupling נמוך - כדי שנצטרך להתקין רק מאגר אחד מהן בעת שינוי בלוגיקה. לכן נשאף לחלק למאגרים קטנים ככל הניתן כל עוד לא פוגעים ב-cohesion יותר מדי.
- שני מאגרים לא משתפים DB ביניהם, כי זה יוצר coupling מאד גבוה.
- מותרת הצבעה (reference) ממאגר אחד למאגר אחר.
- המאגר הוא product. יש לו lifecycle עצמאי, הוא לא חלק מ-product אחר.
- המאגר הוא בעל המידע. הוא האחראי הסופי לוודא שמידע תקין, קוהרנטי, זמין ומגובה.
- המאגר חושף API סטנדרטי, ומחוייב כלפי לקוחותיו לתאימות לאחור. מאידך, הוא דורש מלקוחותיו להיות תואמים לפנים.
- המאגר דורש מלקוחותיו לחיות עם מצב של eventually consistent, לפחות בכל מה שקשור בעבודה בין מאגרים (אך לא מוגבל לזה).
המטרה בתפיסת המאגרים היא לאפשר לשנות את התרבות הארגונית לתרבות גמישה, ובהתאם לשנות את הצורה שבה אנחנו מפתחים תוכנה:
- לאפשר לצוות לקחת feature, לממש אותו ולהריץ אותו עד ה-production במינימום חיכוך עם צוותים אחרים או עם מנהלים - הם יכולים לשנות ולהשתמש בטכניקות של תאימות לאחור.
- לאפשר לנו לזהות טעויות אפיון, באגים ותקלות מהר ולטפל בהם מהר לפני שהמשתמשים נפגעים. את זה ניתן להשיג ע"י אוסף של טכניקות מעולם ה-MSA, כגון: Mirror Testing, Switch Testing, A/B Testing, ניטור מגמות (בעיקר בהבדל בין גרסאות).
- ובהמשך לקודם - מפסיקים לפחד מטעויות וכשלונות. הטכניקות הנ"ל יחד עם rollback מיידי והתקנה זולה (אפשר לתקן באג ולהתקין באותו יום ב-"לבן"), מאפשרים לנו להוריד מאד את העלות של טעות ובאג, ולכן חופש גדול יותר בפעולה.
- לא לחייב את הלקוח לבחור תכולות לשנה קדימה, אלא להיות איתו בדיאלוג מתמיד ולתת לו את מה שהוא צריך גם בטווח הקצר. כדי לעשות את זה, coupling נמוך יקטין את מספר ההתחייבויות החיצוניות שלנו, וההתקנה המקומית תעשה את תהליך ההתקנה לקל יותר ולכן אפורדבילי לביצוע לעיתים תכופות.
- לאפשר לנו להתאים טכנולוגיה לצורך, וגם להתקדם טכנולוגית בעלות נמוכה יחסית.
- שימוש ב-API סטנדרטי המבוסס על פרוטוקול סטנדרטי (כגון REST ו-MQTT) יאפשר לגורמים מכל רחבי הארגון להתחבר בלי צורך להקים "ממשק" מפורש כמו פעם.
חוץ מזה, למאגרים יש עוד אוסף של יתרונות לעומת הקיים בארגון שלנו כיום, מעצם זה שנוצרת הפרדה בין האפליקציה למאגר. מוביל תפיסת המאגרים בארגון שרטט את זה בשקף (שמובא כאן כטבלה):
הבעייה: TTM ארוך וחוסר רלוונטיות.
הסיבות:
|
המטרה: TTM קצר, תרומה מיידית ליכולות המשתמשים.
הפתרונות:
|
ריבוי מקורות מידע לאותו מידע
|
אמת אחת ואחריות על המידע
|
פורמט מידע קשיח
|
גמישות לשינויים וגרסאות
|
ייצוג שונה למידע באזורים שונים בארגון
|
ייצוג אחיד למידע בארגון
|
עבודה עם מונוליטים
|
פירוק לאפליקציות, שירותים ומאגרים
|
תהליך בדיקות מורכב
|
מכוון תפיסת הבדיקות החדשה
|
ההפרדה בין האפליקציה למאגר, במקרה הזה, מאפשרת סטנדרטיזציה של המאגרים וניהול המידע, ובכך להפוך את המידע להיות "נכס ארגוני" התואם לצרכי הארגון ולא לאפיון של אפליקציה ספציפית.
שינויים ארגוניים
השינוי התרבותי הזה, יחד עם השינוי הארכיטקטוני שמאפשר אותו, צריכים להביא גם שינויים ארגוניים שיאפשרו לנו להפיק את המיטב מהתפיסה הזאת. בין השאר:
- הַסַמְכוּת צריכה לרדת דרגה בהיררכיה (לזוז ימינה בלוח ההאצלות, עוד מידע כאן וכאן) כדי לאפשר לצוותים לנוע מהר יותר בלי לחכות למנהל על כל דבר. הורדת עלות הטעות מאפשרת את זה.
- כל השותפים למוצר צריכים לעבוד יחד - איש ה-product, המאפיין, הארכיטקט, צוות הפיתוח ואנשי ה-ops. כולם צריכים להיות חלק ממחזור העבודה ולהיות מעורבים, לא בהעברת אחריות לשלב הבא בתהליך.
- אוטומציה היא בסיס, לא אפשרות מתקדמת. Unit test מלא למוצר הוא חלק מהסטנדרט, ענן בפיתוח שמאפשר להרים סביבת בדיקה בקליק זה חלק מסביבת הפיתוח של התוכניתן, ואף אחד לעולם לא נוגע בסביבת ה-production שלא דרך push מסודר.
- במקום גופי תשתיות גדולים, מעבירים משקל לשיטת Open Source שבה הצוות שזקוק לתכולה מפתח אותה, בבקרה של צוותים אחרים או אחראי Open Source. אין גופים גדולים שמהווים צוואר בקבוק וסיכון בתוכנית העבודה, אלא אם כן זו תשתית שהיא לחלוטין מחוץ לתחום האפליקציה (כמו מנגנוני security וניטור סטנדרטיים, BI וכד') או מוצר אחד שמשרת את כל הרשת (כמו event bus).
- מנגישים מידע. ה-API ותשתיות ה-Open Source צריכים להיום חשופים בפורטל נגיש לכולם (כלומר לא sharepoint אלא משהו מהיר ונוח) שדרכו אפשר לדעת מה קיים ושימוש ב-npm ונגזרותיו כדי לאפשר לתוכניתן לעבוד בסביבת עבודה מתקדמת עם ניצול מיידי של נכסים קיימים.
- במקום המון סקרים, מעדיפים להגיע כמה שיותר מהר ל-Earliest Testable Product (ראה גם Lean Startup. יש גם הרצאה).
מה הלאה?
מאגרי מידע ו-MSA הם לא סוף הדרך. הם עוד אבני בניין בתהליך שהתחיל מהכרטיסיות המנוקבות, האסמבלר, השפות העיליות, OOP, ארכיטקטורת SOA ועוד הרבה שעברנו בדרך. MSA היא הטכנולוגיה הבשלה הנוכחית למימוש של גמישות ארגונית מקסימאלית. אבל המגמה ממשיכה ומתחזקת, וכבר יש טכנולוגיות שמציעות להיות השלב הבא של גמישות בתוכנה. שתי דוגמאות לטכנולוגיות כאלה:
- Serverless Architecture - ארכיטקטורה שמציעה "להיפתר" מהשרתים בכלל ולאפשר לענן להריץ פונקציות בודדות, ב-scale כראות עיניו, כמעין 'ענן פונקציות'. דוגמא לתשתית כזאת שכבר נמצאת בשימוש ב-production היא AWS Lambda, שבה משלמים לפי milliseconds שהקוד שלנו רץ. למרות שהארכיטקטורה הזאת זוכה לצמיחה גדולה, היא עדיין בחיתוליה ולא ברור שאכן תוכל להחליף את הארכיטקטורה מבוססת השרתים. אבל היא מקצינה עוד יותר את השאיפה של הארגונים לגמישות ולשינויים בקצב גבוה.
- Reactive Programming - תפיסה שמתיימרת להחליף את ה-flow של תוכנה כמו שאנחנו מבינים אותו היום (ובמובן מסויים את OOP כארכיקטורת הקוד הראשית). היא מצויינת בעולם שבו יש הרבה אירועים שזורמים, ומאפשר טיפול מאד גמיש וניתן להרחבה באירועים בזמן אמת. על אף שהיא בשימוש מסויים ב-.Net כבר שנים רבות, היא גם כן עוד בחיתוליה ולא ברור מה המשקל שהיא תתפוס בתוך עולם התוכנה.
עוד תפיסות כאלה ימשיכו ויעלו במעלה הדרך. זה יכול להיות ענן מידע (במקום DB), תקשורת מודולרית (במקום מבנה הרשת הנוכחי, SDN הוא צעד ראשון בכיוון) או אפילו מעבר להתנהגות סטטיסטית מבוססת אוסמוזה, בדומה למנגנונים בגוף האנושי.
הידיעה שהעולם ישתנה, וישתנה מהר, חייבת להיות בבסיס התרבות של ארגון שרוצה לתת מענה טוב ללקוחות שלו לאורך זמן, וחייבת להיות בבסיס הארכיטקטורה שסביבה הוא בונה את המערכת שלו, כדי שבפעם הבאה לא נצטרך שוב 10 שנים של פיתוח עם זמן ביניים מאד לא נעים כדי להתקדם בטכנולוגיה, שבסופם נגלה שאנחנו עדיין מאחור.
ושוב: מי שגמיש מנצח.
נספח א' - קישורים שימושיים נוספים
בנוסף על כל הלינקים שהופיעו במסמך, עוד כמה לינקים שימושיים:
קישור
|
לינק
|
דף עם ריכוז גדול של סטטיסטיקות
| |
מידע על התיאוריה של MSA
|
|
מידע פרקטי על השימוש ב-MSA
|
A page with a great collection of references to articles, thoughts and lectures about MSA. Probably the best you can find if you want to make a real decision or start implementing.
Netflix techbolg - Netflix opens it’s entire architecture to the public, including technics, performance issues and how they resolve them, distribution issues, tools and frameworks, etc.
|
מידע על ארכיטקטורת Consumer Driven Contract
|
|
אין תגובות :
הוסף רשומת תגובה